提示工程基礎

撰寫提示給LLM的方式也很重要。一個精心設計的提示可以獲得更高品質的回應。但像_prompt_和_prompt engineering_這樣的術語究竟意味著什麼?我該如何改進發送給LLM的提示_input_?這些是我們在本章和下一章中將嘗試回答的問題。
Generative AI 能夠根據使用者請求創建新內容(例如,文字、圖像、音訊、程式碼等)。它使用像 OpenAI 的 GPT("Generative Pre-trained Transformer")系列這樣的_大型語言模型_來實現,這些模型是為使用自然語言和程式碼而訓練的。
用戶現在可以使用熟悉的範式(如聊天)與這些模型互動,無需任何技術專業知識或訓練。這些模型是基於提示的——用戶發送文字輸入(提示)並獲得 AI 回應(完成)。然後他們可以在多輪對話中反覆與 AI 聊天,精煉他們的提示,直到回應符合他們的期望。
"Prompts" 現在成為生成式 AI 應用程式的主要_程式設計介面_,告訴模型該做什麼並影響返回回應的品質。"Prompt Engineering" 是一個快速增長的研究領域,專注於提示的_設計和最佳化_,以大規模提供一致且高品質的回應。
學習目標
在本課程中,我們將學習什麼是提示工程、它為什麼重要,以及如何為給定的模型和應用物件設計更有效的提示。我們將了解提示工程的核心概念和最佳實踐,並學習一個互動式 Jupyter Notebooks "sandbox" 環境,在那裡我們可以看到這些概念應用於真實範例。
在本課結束時,我們將能夠:
- 解釋什麼是提示工程以及為什麼它很重要。
- 描述提示的組成部分及其使用方式。
- 學習提示工程的最佳實踐和技術。
- 使用 OpenAI 端點將所學技術應用於真實範例。
學習沙盒
目前,提示工程更像是一門藝術而非科學。提高我們直覺的最佳方式是_多加練習_,並採用試錯法,將應用領域專業知識與推薦技術和模型特定的最佳化相結合。
Jupyter Notebook 隨附本課程提供了一個 sandbox 環境,您可以在學習過程中或作為程式碼挑戰的一部分來嘗試所學內容。要執行這些練習,您將需要:
- 一個 Azure OpenAI API 金鑰 - 已部署 LLM 的服務端點。
- 一個 Python 執行環境 - Notebook 可以在其中執行。
- 本地環境變數 - 完成設定步驟以準備好。
筆記本附帶_入門_練習 - 但我們鼓勵你添加自己的_Markdown_(描述)和_程式碼_(提示請求)部分,以嘗試更多範例或想法 - 並建立你對提示設計的直覺。
圖解指南
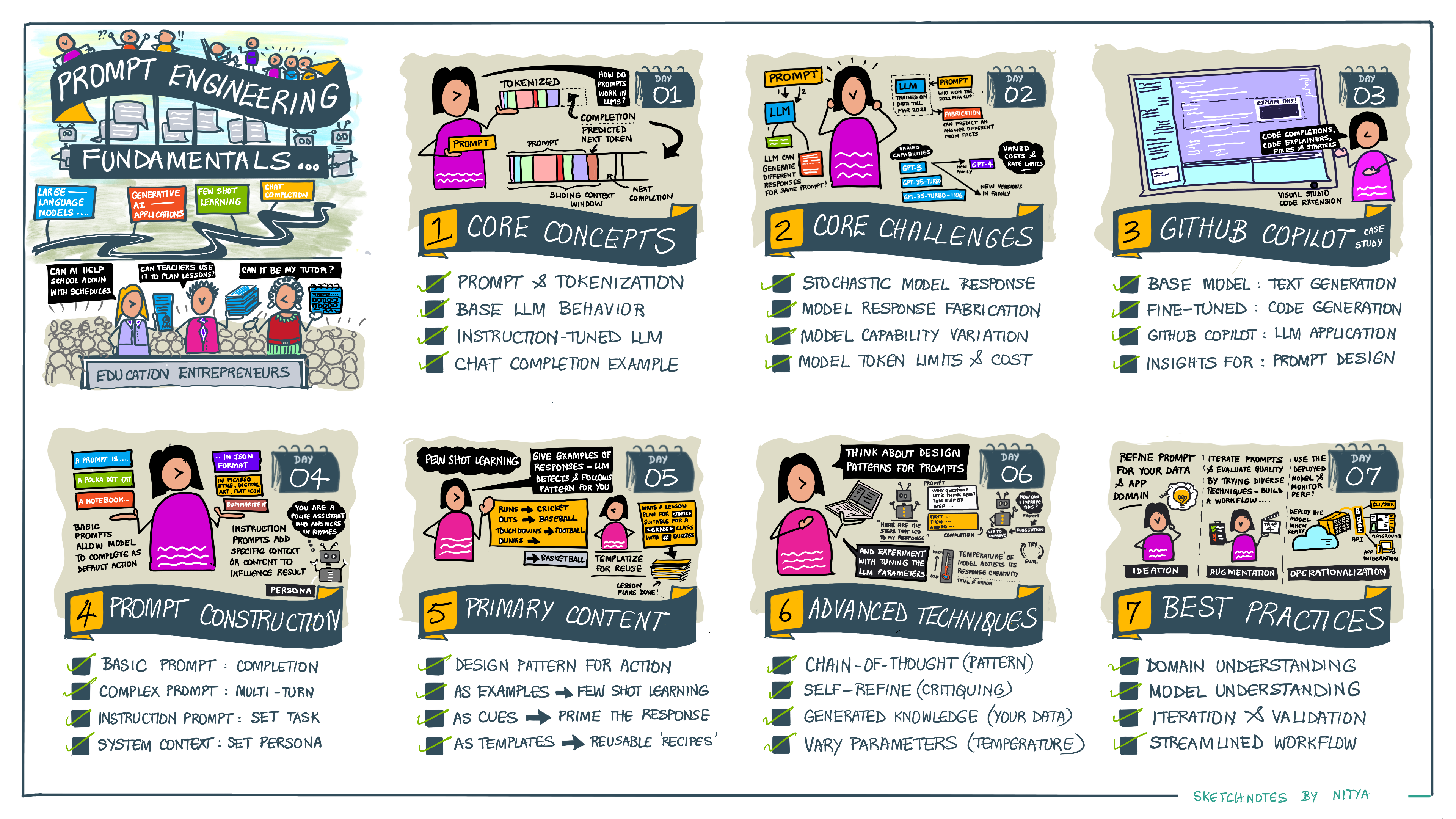
想在深入學習之前了解本課程涵蓋的主要內容嗎?查看這本插圖指南,它會讓你了解涵蓋的主要主題,以及每個主題中你需要思考的關鍵要點。課程路線圖將帶你從理解核心概念和挑戰開始,然後通過相關的提示工程技術和最佳實踐來解決這些問題。請注意,本指南中的「高級技術」部分指的是本課程下一章節涵蓋的內容。
我們的初創公司
現在,讓我們談談_這個主題_如何與我們的創業使命相關,即將 AI 創新帶入教育。我們希望建構 AI 驅動的_個性化學習_應用程式 - 所以讓我們思考一下我們應用程式的不同使用者如何「設計」提示:
- 管理員可能會要求 AI 分析課程數據以識別覆蓋範圍中的缺口。AI 可以總結結果或使用程式碼將其可視化。
- 教育者可能會要求 AI 為目標受眾和主題生成課程計劃。AI 可以以指定的格式建構個性化計劃。
- 學生可能會要求 AI 在困難的科目上輔導他們。AI 現在可以通過針對他們水平的課程、提示和範例來指導學生。
這只是冰山一角。查看Prompts For Education - 由教育專家策劃的開放原始碼提示函式庫 - 以更廣泛地了解可能性!嘗試在沙盒中執行一些這些提示,或使用 OpenAI Playground 看看會發生什麼!
什麼是提示工程?
我們開始這堂課時,將Prompt Engineering定義為_設計和最佳化_文字輸入(prompts)的過程,以提供一致且高品質的回應(completions)來達到給定的應用目標和模型。我們可以將這視為一個兩步驟的過程:
- 設計 給定模型和目標的初始提示
- 反覆改進 提示以提高回應的品質
這必然是一個需要用戶直覺和努力來獲得最佳結果的反覆試驗過程。所以為什麼這很重要?要回答這個問題,我們首先需要了解三個概念:
- 分詞 = 模型如何「看見」提示
- 基礎 LLMs = 基礎模型如何「處理」提示
- 指令調整 LLMs = 模型現在如何看見「任務」
分詞
一個 LLM 將提示視為_一系列的標記_,不同的模型(或模型的不同版本)可以以不同的方式將相同的提示標記化。由於 LLM 是在標記上訓練的(而不是在原始文本上),提示的標記化方式直接影響生成回應的品質。
為了直觀了解分詞是如何運作的,可以嘗試使用像 OpenAI Tokenizer 這樣的工具。將你的提示複製進去,看看它如何轉換成標記,注意空白字元和標點符號是如何處理的。請注意,此範例顯示的是較舊的 LLM (GPT-3),所以用較新的模型嘗試可能會產生不同的結果。

概念: 基礎模型
一旦提示被標記化,"Base LLM" (或基礎模型) 的主要函式是預測該序列中的標記。由於LLM是基於大量文本資料集訓練的,它們對標記之間的統計關係有很好的理解,並且可以有信心地做出預測。請注意,它們並不理解提示或標記中單詞的_意義_;它們只是看到一個模式,並可以用下一個預測來「完成」它。它們可以繼續預測該序列,直到被使用者干預或某些預先設定的條件終止。
想看看基於提示的完成如何運作?將上述提示輸入到 Azure OpenAI Studio 的Chat Playground中,使用預設設定。系統被配置為將提示視為資訊請求——因此你應該會看到一個滿足此上下文的完成。
但是如果使用者想要看到符合某些標準或任務目標的特定內容呢?這就是_指令調整_的LLM派上用場的地方。
概念: 指令調整 LLMs
一個指令調整的 LLM從基礎模型開始,並使用範例或輸入/輸出對(例如,多輪「訊息」)進行微調,這些範例或對話可以包含明確的指令——AI 的回應嘗試遵循該指令。
這使用了像是人類回饋強化學習(RLHF)這樣的技術,可以訓練模型_遵循指示_和_從回饋中學習_,以便產生更適合實際應用且更符合使用者目標的回應。
讓我們試試看 - 重訪上面的提示,但現在將 系統訊息 更改為提供以下指示作為上下文:
總結提供給你的內容,適合二年級學生。將結果保持在一段內,包含3-5個要點。
看看結果現在如何調整以反映所需的目標和格式?教育者現在可以直接在他們的幻燈片中使用這個回應,適用於那個類別。

為什麼我們需要提示工程?
現在我們知道提示是如何被LLM處理的,讓我們來談談為什麼我們需要提示工程。答案在於當前的LLM提出了許多挑戰,使得在不投入提示建構和最佳化的情況下,更難以實現可靠且一致的完成。例如:
-
模型回應是隨機的。 相同的提示可能會因不同的模型或模型版本產生不同的回應。甚至在不同時間使用相同的模型也可能產生不同的結果。提示工程技術可以通過提供更好的防護措施來幫助我們減少這些變異。
-
模型可能會捏造回應。 模型是用大型但有限的數據集進行預訓練的,這意味著它們缺乏訓練範圍之外的概念知識。因此,它們可能會產生不準確、虛構或直接與已知事實相矛盾的完成。提示工程技術幫助用戶識別和減輕這些捏造,例如,通過要求 AI 提供引用或推理。
-
模型能力會有所不同。 新的模型或模型世代將具有更豐富的能力,但也會帶來成本和複雜性的獨特怪癖和權衡。提示工程可以幫助我們開發最佳實踐和工作流程,以可擴展、無縫的方式抽象出差異並適應特定模型的需求。
讓我們在 OpenAI 或 Azure OpenAI Playground 中看看這個實際運作:
- 使用相同的提示與不同的 LLM 部署(例如, OpenAI, Azure OpenAI, Hugging Face)- 你是否看到了變化?
- 使用相同的提示反覆與_相同的_ LLM 部署(例如, Azure OpenAI playground)- 這些變化有何不同?
製作範例
在本課程中,我們使用術語「捏造」來指代LLM有時因訓練限制或其他約束而生成事實上不正確的資訊的現象。你可能在流行文章或研究論文中也聽過這種現象被稱為_「幻覺」。然而,我們強烈建議使用「捏造」_這個術語,這樣我們就不會因為將人類特徵歸因於機器驅動的結果而無意中擬人化這種行為。這也從術語角度加強了負責任的AI指南,去除了在某些情境下可能被認為具有冒犯性或不包容性的術語。
想了解捏造是如何運作的嗎?想一個提示,指示 AI 生成一個不存在的主題的內容(以確保它不在訓練數據集中)。例如 - 我試過這個提示:
提示: 產生一個關於2076年火星戰爭的課程計劃。
一個網路搜尋顯示,有關火星戰爭的虛構故事(例如,電視劇或書籍)——但沒有發生在2076年。常識也告訴我們,2076年是在未來,因此,不能與真實事件相關聯。
那麼當我們使用不同的 LLM 提供者執行這個提示時會發生什麼情況呢?
回應 1: OpenAI Playground (GPT-35)

回應 2: Azure OpenAI Playground (GPT-35)
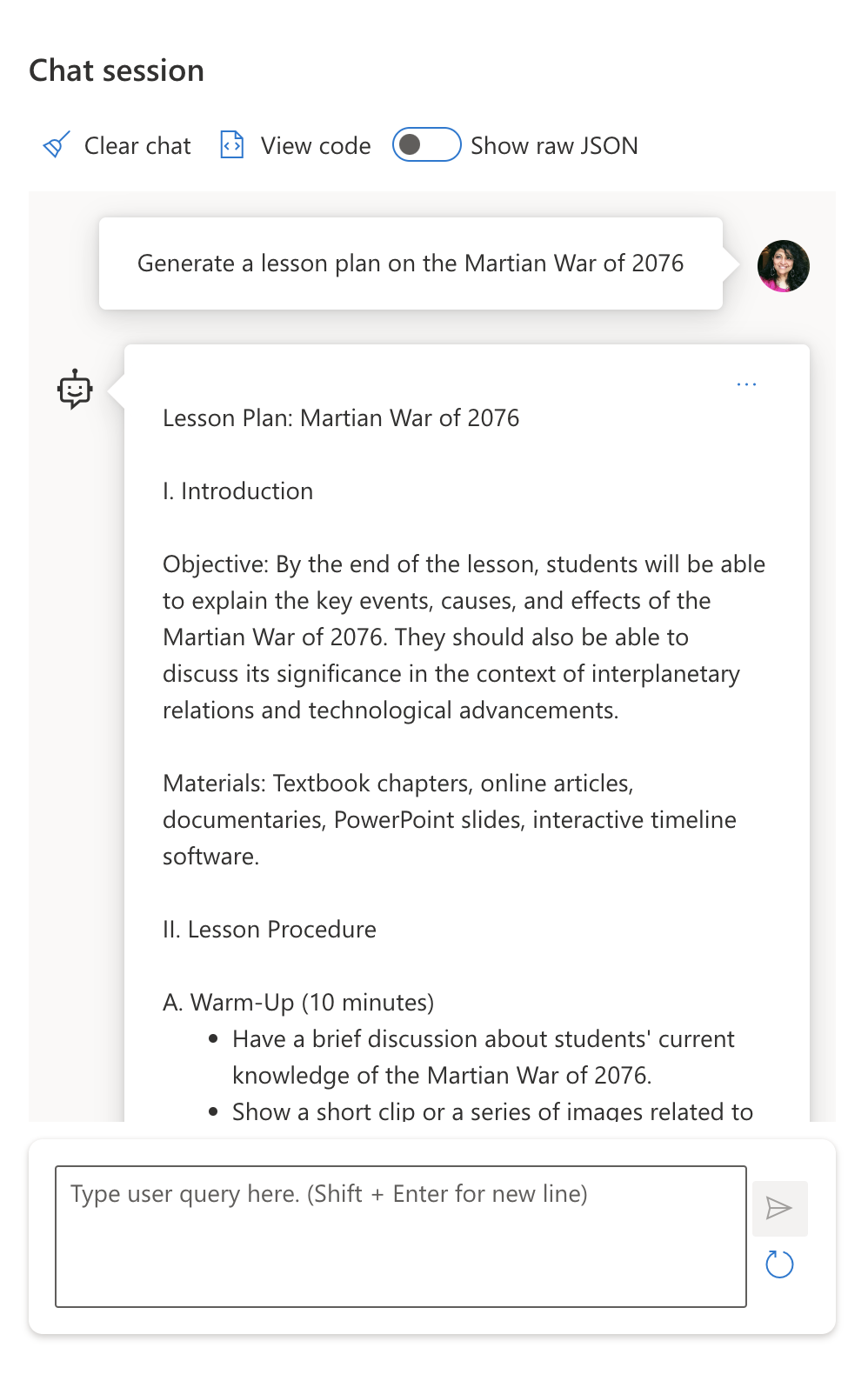
回應 3: : Hugging Face Chat Playground (LLama-2)

正如預期的那樣,由於隨機行為和模型能力的變化,每個模型(或模型版本)產生的回應略有不同。例如,一個模型針對八年級的觀眾,而另一個則假設是高中生。但所有三個模型都生成了可以讓不知情的用戶相信事件是真實的回應。
提示工程技術如_metaprompting_和_溫度配置_可能在某種程度上減少模型的捏造。新的提示工程_架構_也將新工具和技術無縫地整合到提示流程中,以減輕或減少其中一些效果。
案例研究: GitHub Copilot
讓我們通過查看一個案例研究來了解提示工程在現實世界解決方案中的應用: GitHub Copilot。
GitHub Copilot 是你的 "AI Pair Programmer" - 它將文字提示轉換為程式碼完成,並整合到你的開發環境中(例如,Visual Studio Code),提供無縫的使用者體驗。正如以下一系列博客所記錄的那樣,最早的版本是基於 OpenAI Codex 模型 - 工程師們迅速意識到需要微調模型並開發更好的提示工程技術,以提高程式碼品質。7 月,他們推出了一個改進的 AI 模型,超越了 Codex,提供更快的建議。
依照順序閱讀文章,以跟隨他們的學習旅程。
- 2023年5月 | GitHub Copilot 正在變得更了解你的程式碼
- 2023年5月 | 深入 GitHub: 與 GitHub Copilot 背後的 LLMs 合作。
- 2023年6月 | 如何為 GitHub Copilot 撰寫更好的提示。
- 2023年7月 | .. GitHub Copilot 超越 Codex,具有改進的 AI 模型
- 2023年7月 | 開發者的提示工程和 LLMs 指南
- 2023年9月 | 如何構建企業 LLM 應用: 來自 GitHub Copilot 的經驗教訓
你也可以瀏覽他們的工程部落格來查看更多像這篇展示如何應用這些模型和技術來推動實際應用的文章。
提示建構
我們已經了解為什麼提示工程很重要 - 現在讓我們來理解提示是如何_構建_的,這樣我們就可以評估不同的技術以設計更有效的提示。
基本提示
讓我們從基本提示開始:一個沒有其他上下文的文字輸入發送到模型。這裡有一個範例 - 當我們將美國國歌的前幾個字發送到 OpenAI Completion API 時,它會立即_完成_回應的接下來幾行,展示了基本的預測行為。
| Prompt (Input) | Completion (Output) |
|---|---|
| Oh say can you see | It sounds like you're starting the lyrics to "The Star-Spangled Banner," the national anthem of the United States. The full lyrics are ... |
複雜提示
現在讓我們為這個基本提示添加上下文和指示。Chat Completion API 讓我們可以將複雜的提示構建為一組 訊息,包括:
- 輸入/輸出對應反映 使用者 輸入和 助手 回應。
- 系統訊息設定助手行為或個性背景。
請求現在如下所示,其中 tokenization 有效地從上下文和對話中捕捉到相關資訊。現在,改變系統上下文對完成的品質影響與提供的使用者輸入一樣大。
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一個有幫助的助手。"},
{"role": "user", "content": "誰贏得了2020年的世界大賽?"},
{"role": "assistant", "content": "洛杉磯道奇隊贏得了2020年的世界大賽。"},
{"role": "user", "content": "比賽在哪裡舉行?"}
]
)
指令提示
在上述範例中,使用者提示是一個簡單的文字查詢,可以解釋為一個資訊請求。使用_instruction_提示,我們可以使用該文字更詳細地指定任務,為AI提供更好的指導。這裡有一個範例:
| Prompt (Input) | Completion (Output) | Instruction Type |
|---|---|---|
| Write a description of the Civil War | returned a simple paragraph | Simple |
| Write a description of the Civil War. Provide key dates and events and describe their significance | returned a paragraph followed by a list of key event dates with descriptions | Complex |
| Write a description of the Civil War in 1 paragraph. Provide 3 bullet points with key dates and their significance. Provide 3 more bullet points with key historical figures and their contributions. Return the output as a JSON file | returns more extensive details in a text box, formatted as JSON that you can copy-paste to a file and validate as needed | Complex. Formatted. |
主要內容
在上述範例中,提示仍然相當開放,允許 LLM 決定其預訓練資料集中哪一部分是相關的。使用 主要內容 設計模式時,輸入文字被分為兩部分:
- 一個指令 (動作)
- 相關內容 (影響動作)
這裡有一個範例,指示是「用兩句話總結這個」。
| Prompt (Input) | Completion (Output) |
|---|---|
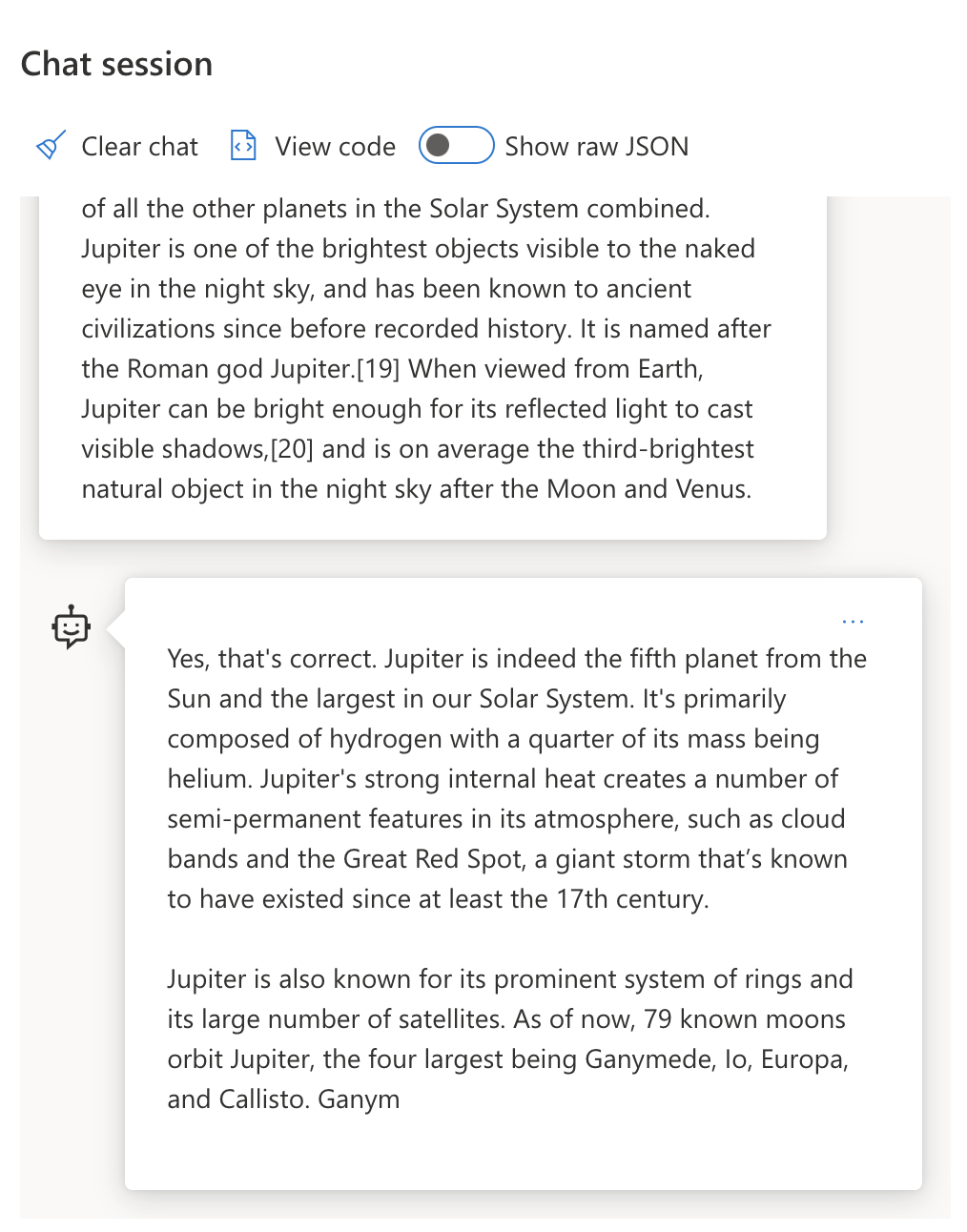
| Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. It is named after the Roman god Jupiter.[19] When viewed from Earth, Jupiter can be bright enough for its reflected light to cast visible shadows,[20] and is on average the third-brightest natural object in the night sky after the Moon and Venus. Summarize this in 2 short sentences |
木星是距離太陽第五顆行星,也是太陽系中最大的行星,並以夜空中最亮的物件之一而聞名。木星以羅馬神祇朱庇特命名,是一顆氣體巨星,其質量是太陽系中所有其他行星總和的兩倍半。 |
主要內容部分可以用於各種方式來推動更有效的指示:
- 範例 - 與其用明確的指令告訴模型該做什麼,不如給它範例,讓它推論出模式。
- 提示 - 在指令後面加上一個「提示」,以引導完成,讓模型朝向更相關的回應。
- 模板 - 這些是可重複使用的提示「秘訣」,帶有佔位符(變數),可以用特定用例的數據來自訂。
讓我們來探索這些實際應用。
使用範例
這是一種方法,你可以使用主要內容來「提供模型」一些給定指令的期望輸出範例,並讓它推論出期望輸出的模式。根據提供的範例數量,我們可以有零範例提示、一範例提示、少量範例提示等。
現在的提示由三個部分組成:
- 任務描述
- 一些所需輸出的範例
- 新範例的開始(這成為隱含的任務描述)
| 學習類型 | 提示 (輸入) | 完成 (輸出) |
|---|---|---|
| 零次學習 | "The Sun is Shining". 翻譯成西班牙文 | "El Sol está brillando". |
| 一次學習 | "The Sun is Shining" => ""El Sol está brillando". "It's a Cold and Windy Day" => |
"Es un día frío y ventoso". |
| 少次學習 | The player ran the bases => Baseball The player hit an ace => Tennis The player hit a six => Cricket The player made a slam-dunk => |
Basketball |
注意我們如何在零樣本提示中提供明確的指示("Translate to Spanish"),但在單樣本提示範例中則會被推論出來。少樣本範例顯示了如何通過增加更多範例,使模型在不增加指示的情況下做出更準確的推論。
提示線索
另一種使用主要內容的技巧是提供_提示_而不是範例。在這種情況下,我們通過_開始_一個反映所需回應格式的程式碼片段來給模型一個正確方向的暗示。然後模型會「接受提示」以繼續這種方式。
| Number of Cues | Prompt (Input) | Completion (Output) |
|---|---|---|
| 0 | Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. Summarize This |
Jupiter is the largest planet in our Solar System and the fifth one from the Sun. It is a gas giant with a mass 1/1000th of the Sun's, but it is heavier than all the other planets combined. Ancient civilizations have known about Jupiter for a long time, and it is easily visible in the night sky.. |
| 1 | Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. Summarize This What we learned is that Jupiter |
is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets combined. It is easily visible to the naked eye and has been known since ancient times. |
| 2 | Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. Summarize This Top 3 Facts We Learned: |
1. Jupiter is the fifth planet from the Sun and the largest in the Solar System. 2. It is a gas giant with a mass one-thousandth that of the Sun... 3. Jupiter has been visible to the naked eye since ancient times ... |
提示範本
一個提示模板是一個_預先定義的提示秘訣_,可以根據需要儲存和重複使用,以大規模推動更一致的使用者體驗。最簡單的形式,它只是一些提示範例的集合,如這個來自 OpenAI 的範例,它提供了互動提示組件(使用者和系統訊息)和 API 驅動的請求格式 - 以支援重複使用。
在它更複雜的形式中,如這個來自 LangChain 的範例,它包含可以用來自各種來源(使用者輸入、系統上下文、外部資料來源等)的資料替換的_佔位符_,以動態生成提示。這使我們能夠建立一個可重複使用的提示函式庫,程式化地在大規模上驅動一致的使用者體驗。
最後,範本的真正價值在於能夠為垂直應用領域建立和發布_提示函式庫_——提示範本現在已_最佳化_,以反映應用特定的上下文或範例,使回應對目標用戶群體更相關和準確。Prompts For Edu儲存庫就是這種方法的一個很好的範例,精選了教育領域的提示函式庫,強調了課程規劃、課程設計、學生輔導等關鍵目標。
支援內容
如果我們將提示建構視為包含一個指令(任務)和一個目標(主要內容),那麼_次要內容_就像是我們提供的額外背景以某種方式影響輸出。這可能是調整參數、格式指令、主題分類等,可以幫助模型_調整_其回應以符合預期的使用者目標或期望。
例如: 給定一個課程目錄,包含課程大綱中所有可用課程的詳細 Metadata (名稱、描述、級別、Metadata 標籤、講師等):
- 我們可以定義一個指令來「總結2023年秋季的課程目錄」
- 我們可以使用主要內容來提供一些所需輸出的範例
- 我們可以使用次要內容來識別前5個感興趣的「標籤」
現在,模型可以按照幾個範例顯示的格式提供摘要 - 但如果結果有多個標籤,它可以優先考慮次要內容中識別的5個標籤。
提示最佳實踐
現在我們知道如何_建構_提示,我們可以開始思考如何_設計_它們以反映最佳實踐。我們可以將這分為兩部分 - 擁有正確的_心態_和應用正確的_技術_。
提示工程心態
提示工程是一個反覆試驗的過程,因此請記住三個廣泛的指導因素:
-
領域理解很重要。 回應的準確性和相關性取決於應用程式或使用者操作的_領域_。運用你的直覺和領域專業知識進一步自訂技術。例如,在系統提示中定義_領域特定的人格_,或在使用者提示中使用_領域特定的範本_。提供反映領域特定上下文的次要內容,或使用_領域特定的提示和範例_來引導模型朝向熟悉的使用模式。
-
模型理解很重要。 我們知道模型本質上是隨機的。但模型實現也可能因其使用的訓練數據集(預訓練知識)、提供的功能(例如,通過 API 或 SDK)以及它們最佳化的內容類型(例如,程式碼 vs. 圖像 vs. 文字)而有所不同。了解你所使用模型的優勢和限制,並利用這些知識來_優先處理任務_或建構_最佳化模型功能的自訂範本_。
-
迭代與驗證很重要。 模型正在快速演變,提示工程技術也是如此。作為領域專家,你可能有其他_你的_特定應用程式的上下文或標準,這些可能不適用於更廣泛的社群。使用提示工程工具和技術來「快速啟動」提示構建,然後使用你的直覺和領域專業知識進行迭代和驗證結果。記錄你的見解並建立一個知識庫(例如,提示函式庫),以便其他人將來可以用作新的基準,進行更快速的迭代。
最佳實踐
現在讓我們來看看Open AI和Azure OpenAI從業者推薦的常見最佳實踐。
| 什麼 | 為什麼 |
|---|---|
| 評估最新模型 | 新模型世代可能具有改進的功能和品質 - 但也可能會產生更高的成本。評估它們的影響,然後做出遷移決策。 |
| 分開指令和上下文 | 檢查您的模型/提供者是否定義了_分隔符_以更清楚地區分指令、主要和次要內容。這可以幫助模型更準確地分配權重給標記。 |
| 具體且清晰 | 提供更多關於所需上下文、結果、長度、格式、風格等的詳細資訊。這將改善回應的品質和一致性。在可重用的模板中捕捉秘訣。 |
| 描述性,使用範例 | 模型可能對「展示和講解」的方法反應更好。從零範例方法開始,給它一個指令(但沒有範例),然後嘗試少量範例作為改進,提供一些所需輸出的範例。使用類比。 |
| 使用提示來啟動完成 | 給它一些可以用作回應起點的引導詞或短語,將其推向所需的結果。 |
| 重複 | 有時您可能需要對模型重複自己。在主要內容之前和之後給出指令,使用指令和提示等。迭代和驗證以查看什麼有效。 |
| 順序很重要 | 您向模型呈現資訊的順序可能會影響輸出,即使在學習範例中也是如此,這要歸功於新近性偏見。嘗試不同的選項以查看什麼最有效。 |
| 給模型一個「退出」 | 給模型一個_後備_完成回應,如果因任何原因無法完成任務,它可以提供這個回應。這可以減少模型生成錯誤或虛假回應的機會。 |
如同任何最佳實踐,請記住,根據模型、任務和領域的不同,你的效果可能會有所不同。將這些作為起點,並反覆試驗以找到最適合你的方法。隨著新模型和工具的推出,不斷重新評估你的提示工程流程,重點關注流程的延展性和回應品質。
作業
恭喜!你完成了這節課!是時候用一些真實範例來測試這些概念和技術了!
在我們的作業中,我們將使用一個 Jupyter Notebook,其中包含您可以互動完成的練習。您也可以使用您自己的 Markdown 和程式碼單元來擴展 Notebook,以便自行探索想法和技術。
要開始,先分叉這個 Repo,然後
- (推薦) 啟動 GitHub Codespaces
- (或者) 複製 repo 到你的本地裝置並使用 Docker Desktop
- (或者) 使用你偏好的 Notebook 執行環境開啟 Notebook。
接下來,設定你的環境變數
- 複製 repo 根目錄中的
.env.copy檔案到.env並填入AZURE_OPENAI_API_KEY、AZURE_OPENAI_ENDPOINT和AZURE_OPENAI_DEPLOYMENT值。回到Learning Sandbox section學習如何操作。
接下來,打開 Jupyter Notebook
- 選擇執行時核心。如果使用選項 1 或 2,只需選擇開發容器提供的預設 Python 3.10.x 核心。
你已經準備好執行這些練習。請注意,這裡沒有_對與錯_的答案——只是通過反覆試驗來探索選項,並為給定的模型和應用領域建立直覺。
因此,本課程中沒有程式碼解決方案部分。相反,筆記本將有標題為 "My Solution:" 的 Markdown 儲存格,顯示一個範例輸出供參考。
知識檢查
以下哪一項是遵循一些合理最佳實踐的良好提示?
- 給我看一張紅色汽車的圖片
- 給我看一張紅色汽車的圖片,品牌為Volvo,型號為XC90,停在懸崖邊,夕陽西下
- 給我看一張紅色汽車的圖片,品牌為Volvo,型號為XC90
A: 2, 這是最好的提示,因為它提供了「什麼」的詳細資訊並進入具體細節(不僅僅是任何車,而是特定的品牌和型號),它還描述了整體設定。3 是次佳的,因為它也包含了很多描述。
🚀 挑戰
看看你是否可以利用 "cue" 技術來完成提示: 完成句子 "Show me an image of red car of make Volvo and "。它會如何回應,你會如何改進它?
很棒的工作!繼續學習
想了解更多不同的提示工程概念嗎?請前往持續學習頁面以找到其他關於此主題的優質資源。
前往第 5 課,我們將探討進階提示技巧!