建構搜尋應用程式

點擊上方圖片觀看本課程的影片
還有比聊天機器人和文本生成更多的LLMs。也可以使用嵌入來建構搜尋應用程式。嵌入是數據的數值表示,也稱為向量,可以用於數據的語義搜尋。
在本課程中,你將為我們的教育新創公司建構一個搜尋應用程式。我們的新創公司是一個非營利組織,為發展中國家的學生提供免費教育。我們的新創公司擁有大量的 YouTube 影片,學生可以用來學習 AI。我們的新創公司希望建構一個搜尋應用程式,讓學生可以通過輸入問題來搜尋 YouTube 影片。
例如,學生可能會輸入「什麼是 Jupyter Notebooks?」或「什麼是 Azure ML」,然後搜尋應用程式會返回與問題相關的 YouTube 影片列表,更好的是,搜尋應用程式會返回影片中回答問題所在位置的連結。
簡介
在本課程中,我們將涵蓋:
- 語義 vs 關鍵字搜尋。
- 什麼是文本嵌入。
- 建立文本嵌入索引。
- 搜尋文本嵌入索引。
學習目標
完成本課程後,你將能夠:
- 說明語義搜尋和關鍵字搜尋之間的區別。
- 解釋什麼是文本嵌入。
- 使用嵌入建立應用程式來搜尋資料。
為什麼要建構搜尋應用程式?
建立搜尋應用程式將幫助你了解如何使用嵌入來搜尋資料。你還將學習如何建構一個學生可以用來快速找到資訊的搜尋應用程式。
這課程包括 Microsoft AI Show YouTube 頻道的 YouTube 文字記錄的嵌入索引。AI Show 是一個教你關於 AI 和機器學習的 YouTube 頻道。嵌入索引包含截至 2023 年 10 月的每個 YouTube 文字記錄的嵌入。你將使用嵌入索引為我們的初創公司建構一個搜尋應用程式。搜尋應用程式會返回一個連結,指向影片中回答問題的位置。這是一個讓學生快速找到所需資訊的好方法。
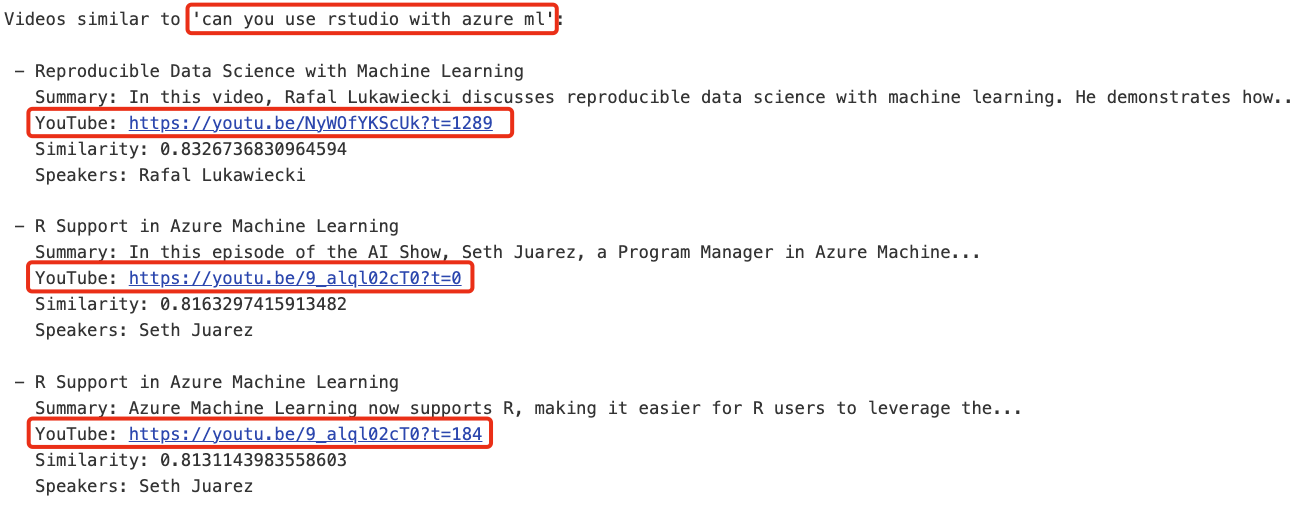
以下是一個針對問題「你可以將 rstudio 與 azure ml 一起使用嗎?」的語義查詢範例。查看 YouTube 連結, 你會看到連結包含一個時間戳記, 它會帶你到影片中回答問題的位置。
什麼是語義搜尋?
現在你可能會想知道,什麼是語義搜尋?語義搜尋是一種搜尋技術,使用查詢中單詞的語義或意義來返回相關結果。
這裡是一個語義搜尋的範例。假設你正在尋找購買一輛車,你可能會搜尋「我的夢想車」,語義搜尋理解你不是在「夢想」一輛車,而是你正在尋找購買你的「理想」車。語義搜尋理解你的意圖並返回相關的結果。另一種方法是「關鍵字搜尋」,它會字面上搜尋關於車的夢想,並且經常返回不相關的結果。
什麼是文本嵌入?
文本嵌入 是一種用於自然語言處理的文本表示技術。文本嵌入是文本的語義數值表示。嵌入用於以機器易於理解的方式表示數據。有許多建構文本嵌入的模型,在本課中,我們將重點放在使用 OpenAI 嵌入模型生成嵌入。
以下是一個範例,假設以下文字來自 AI Show YouTube 頻道其中一集的文字記錄:
今天我們要學習 Azure 機器學習。
我們會將文字傳遞給 OpenAI Embedding API,它會返回由 1536 個數字組成的嵌入(即向量)。向量中的每個數字代表文字的不同方面。為了簡潔起見,以下是向量中的前 10 個數字。
[-0.006655829958617687, 0.0026128944009542465, 0.008792596869170666, -0.02446001023054123, -0.008540431968867779, 0.022071078419685364, -0.010703742504119873, 0.003311325330287218, -0.011632772162556648, -0.02187200076878071, ...]
嵌入索引是如何建立的?
這節課的嵌入索引是用一系列的 Python 腳本建立的。你可以在這節課的 'scripts' 資料夾中的 README 找到這些腳本和說明。你不需要執行這些腳本來完成這節課,因為已經為你提供了嵌入索引。
腳本執行以下操作:
- 每個 YouTube 影片在 AI Show 播放清單中的逐字稿會被下載。
- 使用 OpenAI 函式,嘗試從 YouTube 逐字稿的前 3 分鐘中提取講者姓名。每個影片的講者姓名會儲存在名為
embedding_index_3m.json的嵌入索引中。 - 然後將逐字稿文本分塊成 3 分鐘文本片段。每個片段包括大約 20 個與下一個片段重疊的單詞,以確保片段的嵌入不會被切斷,並提供更好的搜索上下文。
- 然後將每個文本片段傳遞給 OpenAI 聊天 API,將文本摘要為 60 個單詞。摘要也會儲存在嵌入索引
embedding_index_3m.json中。 - 最後,將片段文本傳遞給 OpenAI 嵌入 API。嵌入 API 返回一個包含 1536 個數字的向量,代表該片段的語義意義。片段和 OpenAI 嵌入向量一起儲存在嵌入索引
embedding_index_3m.json中。
向量資料庫
為了簡化課程,Embedding Index 被儲存在名為 embedding_index_3m.json 的 JSON 文件中,並加載到 Pandas DataFrame 中。然而,在生產環境中,Embedding Index 會被儲存在向量資料庫中,例如 Azure Cognitive Search、Redis、Pinecone、Weaviate,僅舉幾例。
理解餘弦相似度
我們已經了解了文本嵌入,下一步是學習如何使用文本嵌入來搜索資料,特別是使用餘弦相似度找到與給定查詢最相似的嵌入。
什麼是餘弦相似度?
餘弦相似度是衡量兩個向量之間相似度的一種方法,你也會聽到這被稱為最近鄰搜尋。要執行餘弦相似度搜尋,你需要使用 OpenAI 嵌入 API 對查詢文本進行_向量化_。然後計算查詢向量與嵌入索引中每個向量之間的_餘弦相似度_。請記住,嵌入索引對每個 YouTube 文字記錄片段都有一個向量。最後,按餘弦相似度對結果進行排序,餘弦相似度最高的文本片段與查詢最相似。
從數學的角度來看,餘弦相似度測量投射在多維空間中兩個向量之間的角度的餘弦值。這種測量是有益的,因為如果兩個文件由於大小而在歐幾里得距離上相距甚遠,它們之間仍然可能有較小的角度,因此具有較高的餘弦相似度。有關餘弦相似度方程的更多資訊,請參見餘弦相似度。
建構你的第一個搜尋應用程式
接下來,我們將學習如何使用 Embeddings 建構一個搜尋應用程式。該搜尋應用程式將允許學生通過輸入問題來搜尋影片。搜尋應用程式將返回與問題相關的影片列表。搜尋應用程式還將返回影片中回答問題的位置連結。
此解決方案是在 Windows 11、macOS 和 Ubuntu 22.04 上使用 Python 3.10 或更高版本建構和測試的。你可以從 python.org 下載 Python。
作業 - 建構搜尋應用程式,以便學生使用
我們在本課開始時介紹了我們的初創公司。現在是時候讓學生們建構一個搜尋應用程式來進行他們的評估。
在此作業中,你將建立 Azure OpenAI 服務來建構搜尋應用程式。你將建立以下的 Azure OpenAI 服務。你需要一個 Azure 訂閱來完成此作業。
啟動 Azure Cloud Shell
- 登入 Azure 入口網站。
- 選擇 Azure 入口網站右上角的 Cloud Shell 圖示。
- 選擇 Bash 作為環境類型。
建立資源群組
對於這些指示,我們使用位於美國東部名為"semantic-video-search"的資源群組。 你可以更改資源群組的名稱,但在更改資源的位置時, 請檢查模型可用性表。
az group create --name semantic-video-search --location eastus
建立 Azure OpenAI Service 資源
從 Azure Cloud Shell 執行以下命令以建立 Azure OpenAI Service 資源。
az cognitiveservices account create --name semantic-video-openai --resource-group semantic-video-search \
--location eastus --kind OpenAI --sku s0
取得此應用程式中使用的端點和金鑰
從 Azure Cloud Shell 執行以下命令以獲取 Azure OpenAI Service 資源的端點和金鑰。
az cognitiveservices account show --name semantic-video-openai \
--resource-group semantic-video-search | jq -r .properties.endpoint
az cognitiveservices account keys list --name semantic-video-openai \
--resource-group semantic-video-search | jq -r .key1
部署 OpenAI 嵌入模型
從 Azure Cloud Shell 執行以下命令來部署 OpenAI 嵌入模型。
az cognitiveservices account deployment create \
--name semantic-video-openai \
--resource-group semantic-video-search \
--deployment-name text-embedding-ada-002 \
--model-name text-embedding-ada-002 \
--model-version "2" \
--model-format OpenAI \
--sku-capacity 100 --sku-name "Standard"
解決方案
打開 解決方案筆記本 在 GitHub Codespaces 並按照 Jupyter Notebook 中的說明進行操作。
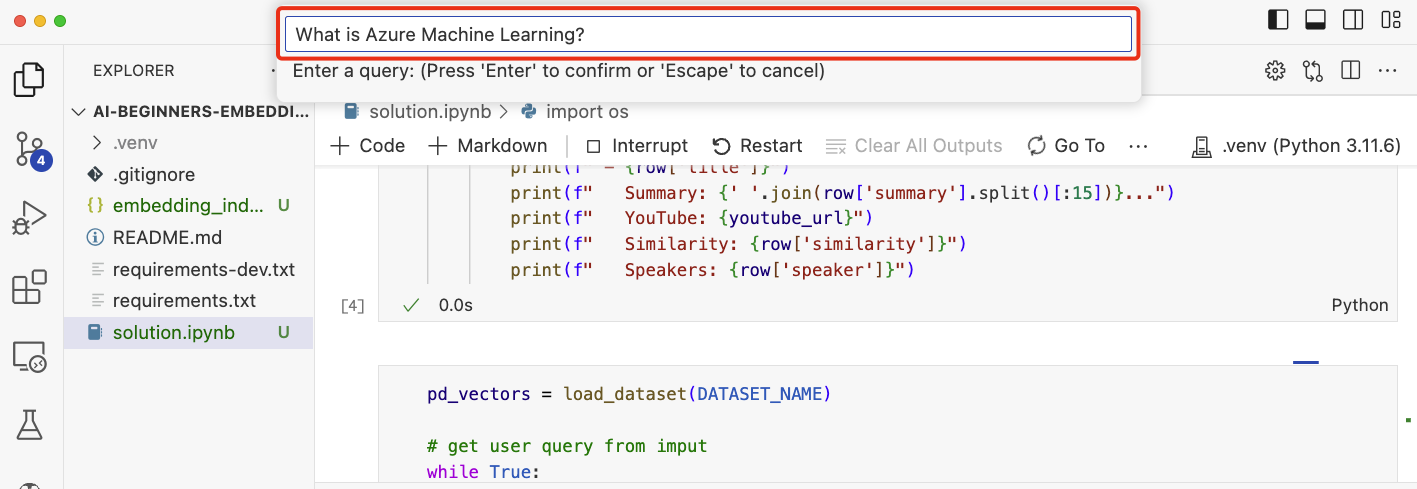
當你執行筆記本時,系統會提示你輸入查詢。輸入框看起來會像這樣:
很棒的工作!繼續學習
完成本課程後,請查看我們的生成式 AI 學習集合以繼續提升您的生成式 AI 知識!
前往第 9 課,我們將看看如何建構影像生成應用程式!