檢索增強生成(RAG)和向量資料庫

在搜尋應用課程中,我們簡要學習了如何將自己的資料整合到大型語言模型(LLMs)中。在本課程中,我們將深入探討在LLM應用中將資料基礎化的概念、過程的機制以及儲存資料的方法,包括嵌入和文本。
影片即將推出
簡介
在本課程中,我們將涵蓋以下內容:
-
介紹 RAG,它是什麼以及為什麼在 AI(人工智慧)中使用它。
-
了解什麼是向量資料庫並為我們的應用程式建立一個。
-
一個關於如何將 RAG 整合到應用程式中的實際範例。
學習目標
完成本課程後,你將能夠:
-
解釋 RAG 在資料檢索和處理中的重要性。
-
設定 RAG 應用並將您的資料接入 LLM
-
在 LLM 應用中有效整合 RAG 和向量資料庫。
我們的場景: 使用我們自己的資料增強我們的 LLMs
為了這節課,我們希望將我們自己的筆記添加到教育創業中,這樣可以讓聊天機器人獲取更多關於不同主題的資訊。使用我們已有的筆記,學習者將能夠更好地學習和理解不同的主題,使他們更容易復習考試。要建立我們的情境,我們將使用:
-
Azure OpenAI:我們將用來建立我們聊天機器人的 LLM -
AI for beginners' lesson on Neural Networks: 這將是我們 LLM 的基礎資料 -
Azure AI Search和Azure Cosmos DB:用來儲存我們資料並建立搜尋索引的向量資料庫
使用者將能夠從他們的筆記中建立練習測驗、修訂抽認卡並將其摘要為簡明的概述。要開始,讓我們看看什麼是 RAG 以及它如何運作:
檢索增強生成 (RAG)
LLM 驅動的聊天機器人處理用戶提示以生成回應。它被設計為互動的,並與用戶在廣泛的主題上進行交流。然而,它的回應僅限於提供的上下文和其基礎訓練數據。例如,GPT-4 的知識截止於 2021 年 9 月,這意味著它缺乏對此期間之後發生的事件的了解。此外,用於訓練 LLM 的數據排除了機密資訊,如個人筆記或公司的產品手冊。
RAGs(檢索增強生成)的工作原理
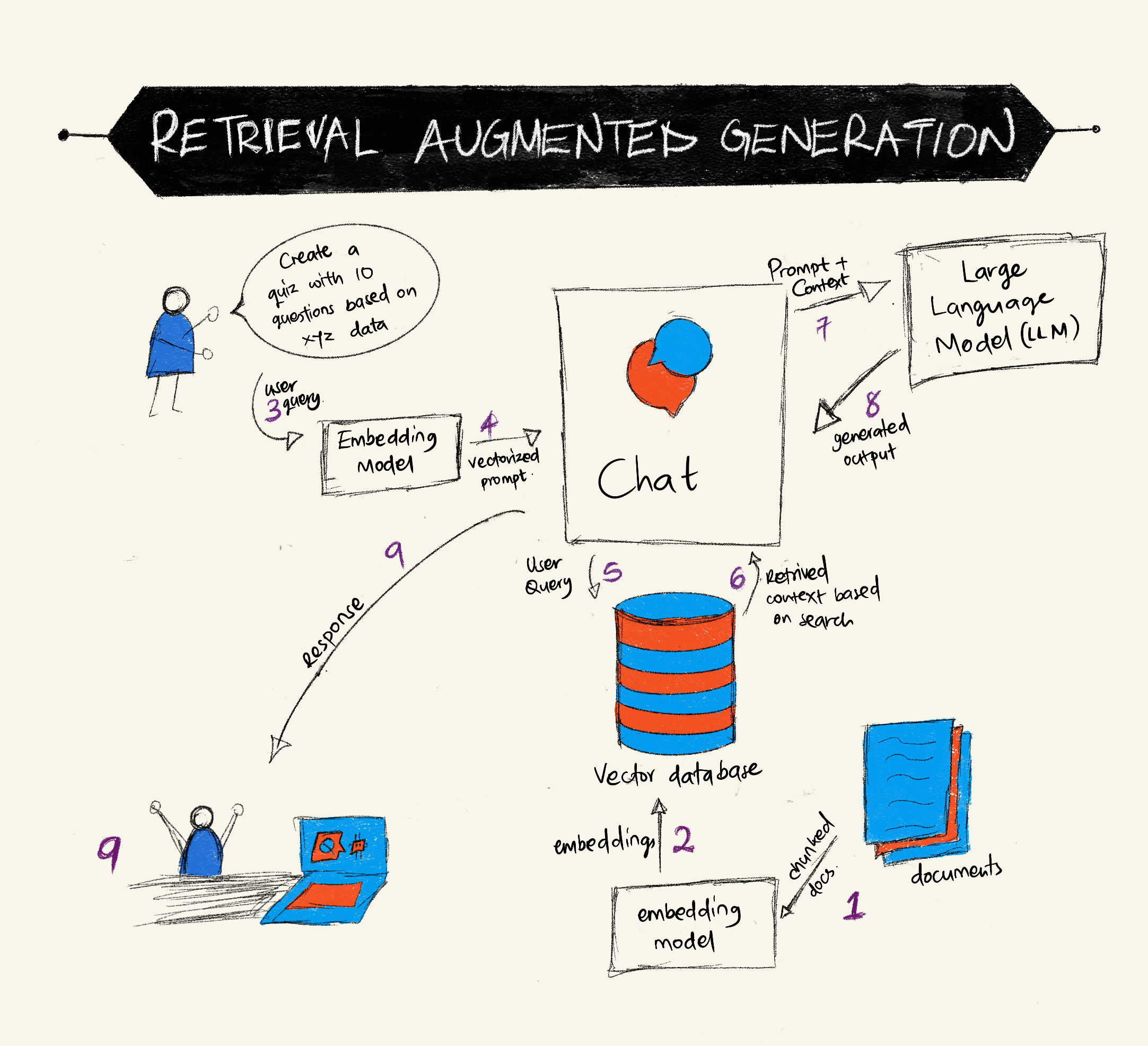
假設你想要部署一個從筆記中建立測驗的聊天機器人,你將需要連接到知識庫。這就是 RAG 派上用場的地方。RAG 的運作方式如下:
-
知識庫: 在檢索之前,這些文件需要被攝取和預處理,通常是將大型文件分解成較小的部分,將它們轉換為文本嵌入並存儲在資料庫中。
-
用戶查詢: 用戶提出問題
-
檢索: 當用戶提出問題時,嵌入模型會從我們的知識庫中檢索相關資訊,以提供更多將被納入提示的上下文。
-
增強生成: LLM 根據檢索到的數據增強其回應。這使得生成的回應不僅基於預訓練數據,還基於新增上下文中的相關資訊。檢索到的數據用於增強 LLM 的回應。然後 LLM 向用戶的問題返回答案。
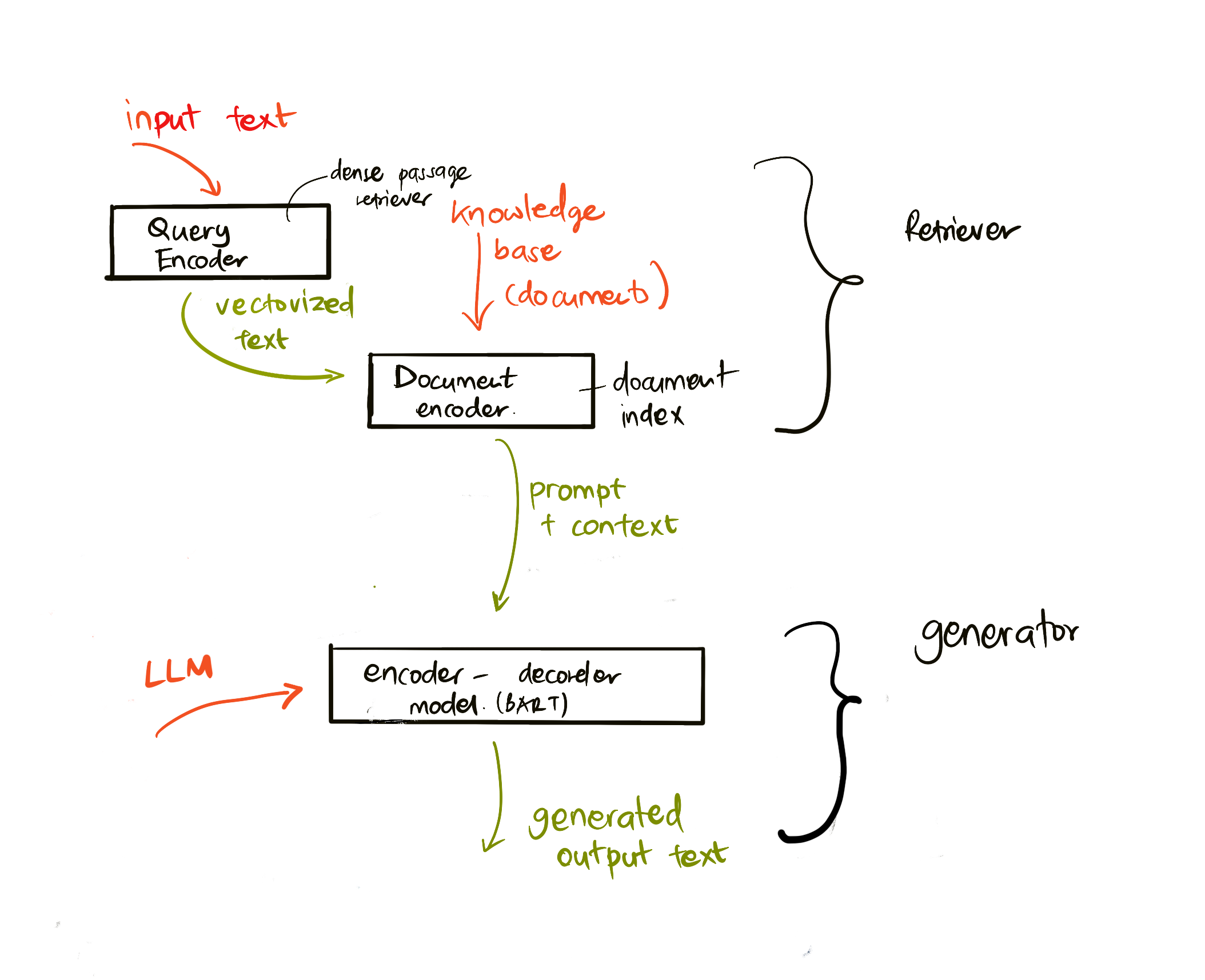
RAGs 的架構是使用由兩部分組成的 transformers 實現的: 一個編碼器和一個解碼器。例如,當使用者提出問題時,輸入文字會被「編碼」成捕捉單詞意義的向量,這些向量會被「解碼」到我們的文件索引中,並根據使用者查詢生成新文字。LLM 使用編碼器-解碼器模型來生成輸出。
根據提議的論文:Retrieval-Augmented Generation for Knowledge intensive NLP (natural language processing software) Tasks實現 RAG 的兩種方法是:
-
RAG-Sequence 使用檢索到的文件來預測對用戶查詢的最佳答案
-
RAG-Token 使用文件生成下一個標記,然後檢索它們來回答用戶的查詢
為什麼要使用 RAGs?
-
資訊豐富度: 確保文字回應是最新且符合現況。因此,通過訪問內部知識庫來增強在特定領域任務上的表現。
-
通過利用知識庫中的可驗證數據來減少捏造,為用戶查詢提供上下文。
-
它是成本效益的,因為與微調LLM相比,它們更經濟。
建立知識庫
我們的應用程式基於我們的個人資料,即 AI 初學者課程中的神經網路課程。
向量資料庫
一個向量資料庫,不同於傳統資料庫,是一種專門設計來儲存、管理和搜尋嵌入向量的資料庫。它儲存文件的數值表示。將資料分解為數值嵌入使我們的 AI 系統更容易理解和處理這些資料。
我們將嵌入儲存在向量資料庫中,因為LLM有接受作為輸入的token數量限制。由於無法將整個嵌入傳遞給LLM,我們需要將它們分解成塊,當使用者問問題時,最像問題的嵌入將與提示一起返回。分塊還可以減少通過LLM傳遞的token數量的成本。
一些流行的向量資料庫包括 Azure Cosmos DB、Clarifyai、Pinecone、Chromadb、ScaNN、Qdrant 和 DeepLake。你可以使用以下命令透過 Azure CLI 建立一個 Azure Cosmos DB 模型:
az login
az group 建立 -n <resource-group-name> -l <location>
az cosmosdb 建立 -n <cosmos-db-name> -r <resource-group-name>
az cosmosdb list-keys -n <cosmos-db-name> -g <resource-group-name>
從文本到嵌入
在我們儲存資料之前,我們需要先將其轉換為向量嵌入,然後再儲存在資料庫中。如果你正在處理大型文件或長文本,可以根據預期的查詢將它們分塊。分塊可以在句子層級或段落層級進行。由於分塊從周圍的詞語中衍生出意義,你可以為分塊添加一些其他的上下文,例如,添加文件標題或在分塊前後包含一些文本。你可以按如下方式分塊資料:
def split_text(文字, 最大長度, 最小長度):
單詞 = 文字.split()
塊 = []
當前塊 = []
for 單詞 in 單詞:
當前塊.append(單詞)
if len(' '.join(當前塊)) < 最大長度 and len(' '.join(當前塊)) > 最小長度:
塊.append(' '.join(當前塊))
當前塊 = []
# 如果最後一塊沒有達到最小長度,無論如何都要添加
if 當前塊:
塊.append(' '.join(當前塊))
return 塊
一旦分塊後,我們可以使用不同的嵌入模型來嵌入我們的文本。您可以使用的一些模型包括: word2vec、OpenAI 的 ada-002、Azure Computer Vision 等等。選擇使用的模型將取決於您使用的語言、編碼的內容類型(文本/圖像/音頻)、它可以編碼的輸入大小以及嵌入輸出的長度。
範例使用 OpenAI 的 text-embedding-ada-002 模型嵌入文字如下:
檢索和向量搜尋
當使用者提出問題時,檢索器會使用查詢編碼器將其轉換為向量,然後在我們的文件搜尋索引中搜尋與輸入相關的向量。完成後,它會將輸入向量和文件向量轉換為文字,並通過 LLM。
檢索
檢索發生在系統嘗試從索引中快速找到滿足搜索標準的文件時。檢索器的目標是獲取將用於提供上下文並基於您的數據定位LLM的文件。
在我們的資料庫中執行搜尋有幾種方法,例如:
-
關鍵字搜尋 - 用於文字搜尋
-
語意搜尋 - 使用單詞的語意
-
向量搜尋 - 使用嵌入模型將文件從文字轉換為向量表示。檢索將通過查詢向量表示最接近用戶問題的文件來完成。
-
混合 - 關鍵字搜尋和向量搜尋的結合。
在資料庫中沒有與查詢相似的回應時,檢索會面臨挑戰,系統將返回他們能獲得的最佳資訊。然而,你可以使用一些策略,比如設定相關性的最大距離或使用結合關鍵字和向量搜索的混合搜索。在本課中,我們將使用混合搜索,結合向量和關鍵字搜索。我們將把數據存儲到一個數據框中,列包含了數據塊以及嵌入。
向量相似度
檢索器將在知識資料庫中搜尋相近的嵌入,最接近的鄰居,因為它們是相似的文本。在使用者提出查詢的情況下,首先會嵌入查詢,然後與相似的嵌入進行匹配。用來衡量不同向量相似度的常見方法是基於兩個向量之間角度的余弦相似度。
我們可以使用其他替代方法來測量相似性,例如歐幾里得距離(即向量端點之間的直線)和點積(測量兩個向量對應元素的乘積之和)。
搜尋索引
在進行檢索時,我們需要在執行搜尋之前為我們的知識庫建構一個搜尋索引。索引將儲存我們的嵌入並且即使在大型資料庫中也能快速檢索到最相似的區塊。我們可以使用以下方式在本地建立我們的索引:
from sklearn.neighbors import NearestNeighbors
embeddings = flattened_df['embeddings'].to_list()
# 建立搜尋索引
nbrs = NearestNeighbors(n_neighbors=5, algorithm='ball_tree').fit(embeddings)
# 要查詢索引,可以使用 kneighbors 方法
distances, indices = nbrs.kneighbors(embeddings)
重新排序
一旦你查詢了資料庫,你可能需要將結果從最相關的排序。一個重新排序的LLM利用機器學習通過將搜索結果從最相關的排序來提高其相關性。使用Azure AI Search,重新排序會自動為你完成,使用語義重新排序器。以下是一個使用最近鄰重新排序如何工作的範例:
# 找到最相似的文件
distances, indices = nbrs.kneighbors([query_vector])
index = []
# 列印最相似的文件
for i in range(3):
index = indices[0][i]
for index in indices[0]:
print(flattened_df['chunks'].iloc[index])
print(flattened_df['path'].iloc[index])
print(flattened_df['distances'].iloc[index])
else:
print(f"Index {index} not found in DataFrame")
將所有內容整合在一起
最後一步是將我們的 LLM 添加到混合中,以便能夠獲得基於我們資料的回應。我們可以如下實現:
user_input = "什麼是感知器?"
def chatbot(user_input):
# 將問題轉換為查詢向量
query_vector = create_embeddings(user_input)
# 找到最相似的文件
distances, indices = nbrs.kneighbors([query_vector])
# 將文件添加到查詢中以提供上下文
history = []
for index in indices[0]:
history.append(flattened_df['chunks'].iloc[index])
# 結合歷史記錄和用戶輸入
history.append(user_input)
# 建立一個訊息物件
messages=[
{"role": "system", "content": "你是一個幫助解答 AI 問題的 AI 助手。"},
{"role": "user", "content": history[-1]}
]
# 使用聊天完成來生成回應
response = openai.chat.completions.create(
model="gpt-4",
temperature=0.7,
max_tokens=800,
messages=messages
)
return response.choices[0].message
chatbot(user_input)
評估我們的應用程式
評估指標
-
回應的品質確保其聽起來自然、流暢且像人類
-
資料的基礎性: 評估回應是否來自提供的文件
-
相關性: 評估回應是否符合並與所問問題相關
-
流暢度 - 回應在語法上是否合理
使用 RAG (檢索增強生成) 和向量資料庫的用例
在許多不同的使用案例中,函式呼叫可以改善您的應用程式,例如:
-
問答: 將公司的資料基礎連結到一個可以讓員工提問的聊天中。
-
推薦系統: 你可以建立一個系統來匹配最相似的值,例如電影、餐廳等等。
-
聊天機器人服務: 你可以儲存聊天歷史並根據使用者資料個性化對話。
-
基於向量嵌入的圖片搜尋,在進行圖像識別和異常檢測時非常有用。
摘要
我們已經涵蓋了從將資料添加到應用程式、使用者查詢和輸出的RAG基本領域。為了簡化RAG的建立,你可以使用如Semanti Kernel、Langchain或Autogen等框架。
作業
要繼續學習檢索增強生成(RAG),你可以建構:
-
使用您選擇的框架為應用程式建構前端
-
利用框架(LangChain 或 Semantic Kernel)重新建構您的應用程式。
恭喜完成這節課 👏。
學習不止於此,繼續旅程
完成本課程後,請查看我們的生成式 AI 學習集合以繼續提升您的生成式 AI 知識!