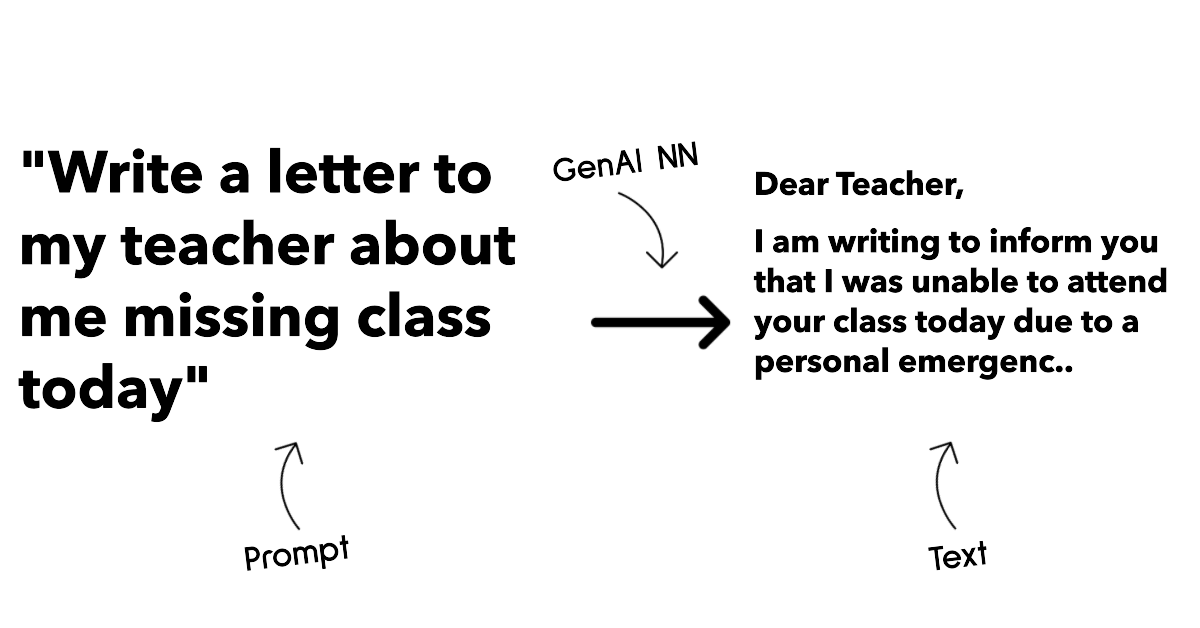
探索和比較不同的 LLMs

點擊上方圖片觀看本課程的影片
隨著上一課,我們已經看到生成式 AI 如何改變技術格局、大型語言模型(LLMs)如何運作以及企業(如我們的初創公司)如何將它們應用於其使用案例並成長!在本章中,我們將比較和對比不同類型的大型語言模型(LLMs),以了解它們的優缺點。
我們初創公司旅程的下一步是探索目前的LLM領域,並了解哪些適合我們的使用案例。
簡介
本課程將涵蓋:
- 當前環境中不同類型的 LLMs。
- 在 Azure 中測試、迭代和比較不同的模型以適應您的使用案例。
- 如何部署 LLM。
學習目標
完成本課程後,你將能夠:
- 選擇適合您使用案例的模型。
- 了解如何測試、迭代和改進模型的性能。
- 知道企業如何部署模型。
了解不同類型的 LLMs
LLMs 可以根據其架構、訓練數據和使用案例進行多種分類。了解這些差異將幫助我們的初創公司為場景選擇合適的模型,並了解如何測試、迭代和改進性能。
有許多不同類型的 LLM 模型,你選擇的模型取決於你打算如何使用它們、你的數據、你準備支付多少以及更多。
根據您是否打算使用模型來生成文本、音訊、影片、圖像等,您可能會選擇不同類型的模型。
-
音訊和語音識別. 為此目的,Whisper 型模型是一個很好的選擇,因為它們是通用的並且針對語音識別。它在多樣化的音訊上進行訓練,能夠執行多語言的語音識別。了解更多關於Whisper 型模型。
-
圖像生成. 對於圖像生成,DALL-E 和 Midjourney 是兩個非常知名的選擇。DALL-E 由 Azure OpenAI 提供。 閱讀更多關於 DALL-E 的資訊 以及本課程的第九章。
-
文本生成. 大多數模型都是針對文本生成進行訓練的,您可以從 GPT-3.5 到 GPT-4 中選擇多種選擇。它們的成本不同,其中 GPT-4 是最昂貴的。值得查看 Azure OpenAI playground 來評估哪個模型在能力和成本方面最適合您的需求。
-
多模態. 如果您希望處理輸入和輸出中的多種類型數據,您可能需要查看像 gpt-4 turbo with vision 或 gpt-4o 這樣的模型 - 最新發布的 OpenAI 模型 - 它們能夠將自然語言處理與視覺理解相結合,通過多模態介面實現互動。
選擇一個模型意味著你會獲得一些基本功能,但這可能還不夠。通常你會有一些公司特定的數據需要告訴LLM。有幾種不同的方法可以解決這個問題,更多內容將在接下來的部分中介紹。
Foundation Models versus LLMs
術語 Foundation Model 由史丹佛研究人員創造,並定義為符合某些標準的 AI 模型,例如:
- 它們使用無監督學習或自我監督學習進行訓練, 意味著它們在未標記的多模態資料上進行訓練,並且不需要人類註釋或標記資料來進行訓練過程。
- 它們是非常大的模型, 基於非常深的神經網絡,訓練了數十億個參數。
- 它們通常旨在作為其他模型的「基礎」, 意味著它們可以作為其他模型的起點,通過微調來建構。
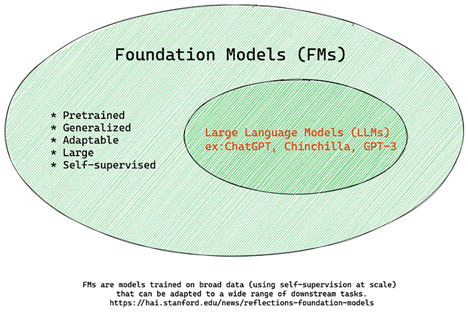
圖片來源: Essential Guide to Foundation Models and Large Language Models | by Babar M Bhatti | Medium
為了進一步澄清這一區別,讓我們以ChatGPT為例。為了建構第一版的ChatGPT,一個名為GPT-3.5的模型作為基礎模型。這意味著OpenAI使用了一些特定於聊天的資料來建立一個調整過的GPT-3.5版本,專門在對話場景中表現良好,例如聊天機器人。
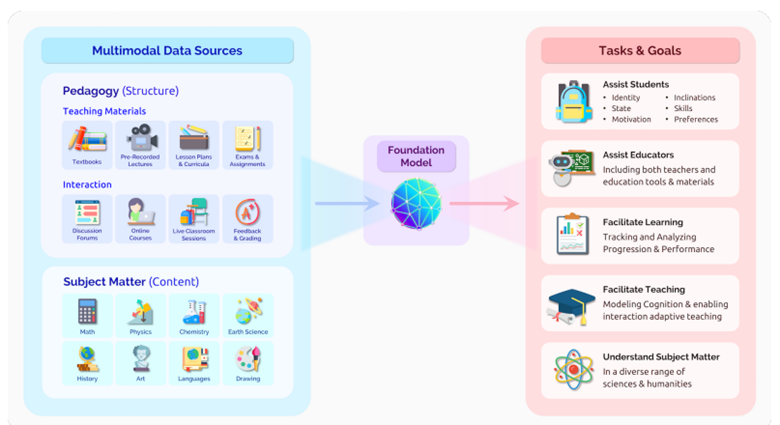
圖片來源: 2108.07258.pdf (arxiv.org)。
開放原始碼 versus 專有模型
另一種分類 LLMs 的方式是它們是開放原始碼還是專有的。
開放原始碼模型是公開提供給大眾使用的模型,任何人都可以使用。這些模型通常由創建它們的公司或研究社群提供。這些模型允許被檢查、修改和自訂,以適應LLM的各種使用案例。然而,它們並不總是針對生產使用進行最佳化,性能可能不如專有模型。此外,開放原始碼模型的資金可能有限,可能不會長期維護或更新最新的研究。受歡迎的開放原始碼模型範例包括Alpaca、Bloom和LLaMA。
專有模型是由公司擁有且不對公眾開放的模型。這些模型通常針對生產用途進行最佳化。然而,它們不允許被檢查、修改或針對不同的使用案例進行自訂。此外,它們並不總是免費提供,可能需要訂閱或支付費用才能使用。而且,使用者無法控制用於訓練模型的數據,這意味著他們應該信任模型擁有者來確保對數據隱私和負責任使用 AI 的承諾。流行的專有模型範例包括OpenAI models、Google Bard或Claude 2。
嵌入對比圖像生成對比文本和程式碼產生器
LLM 也可以根據它們生成的輸出來分類。
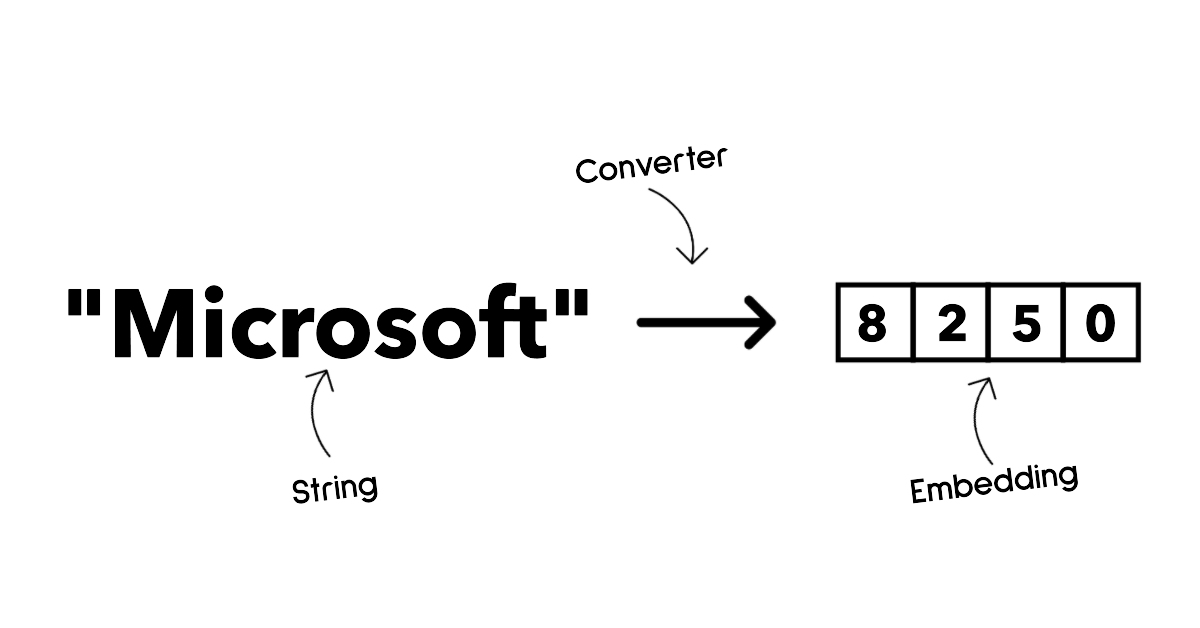
嵌入是一組可以將文本轉換為數字形式的模型,稱為嵌入,這是輸入文本的數字表示。嵌入使機器更容易理解單詞或句子之間的關係,並且可以作為其他模型的輸入,例如分類模型或在數據上表現更好的聚類模型。嵌入模型通常用於遷移學習,其中模型是為有大量數據的代理任務建構的,然後模型權重(嵌入)被重新用於其他下游任務。這類的範例是OpenAI embeddings。
圖像生成模型是生成圖像的模型。這些模型通常用於圖像編輯、圖像合成和圖像翻譯。圖像生成模型通常在大型圖像數據集上進行訓練,例如 LAION-5B,並可用於生成新圖像或使用修補、超分辨率和上色技術編輯現有圖像。範例包括 DALL-E-3 和 Stable Diffusion models。
文本和程式碼產生器模型是生成文本或程式碼的模型。這些模型通常用於文本摘要、翻譯和問答。文本生成模型通常在大型文本數據集上訓練,例如BookCorpus,可以用來生成新文本或回答問題。程式碼產生器模型,例如CodeParrot,通常在大型程式碼數據集上訓練,例如GitHub,可以用來生成新程式碼或修復現有程式碼中的錯誤。
編碼器-解碼器與僅解碼器
為了討論不同類型的LLM架構,讓我們用一個類比來說明。
想像一下,你的經理給你一個任務,為學生編寫一個測驗。你有兩個同事;一個負責建立內容,另一個負責審查它們。
內容創作者就像一個解碼器模型,他們可以查看主題並看到你已經寫了什麼,然後基於此編寫課程。他們非常擅長撰寫引人入勝且資訊豐富的內容,但他們不太擅長理解主題和學習目標。一些解碼器模型的範例是GPT系列模型,例如GPT-3。
審查者就像一個僅有編碼器的模型,他們查看編寫的課程和答案,注意它們之間的關係並理解上下文,但他們不擅長生成內容。僅有編碼器模型的一個範例是BERT。
想像一下,我們也可以有一個人能夠建立和審查測驗,這是一個編碼器-解碼器模型。一些範例是 BART 和 T5。
服務 versus 模型
現在,讓我們來談談服務和模型之間的區別。服務是由雲服務提供商提供的產品,通常是模型、資料和其他元件的組合。模型是服務的核心元件,通常是一個基礎模型,例如一個 LLM。
服務通常針對生產使用進行最佳化,並且通常比模型更易於使用,通過圖形用戶界面。然而,服務並不總是免費提供,可能需要訂閱或支付費用來使用,以換取利用服務擁有者的設備和資源,優化開支並輕鬆擴展。服務的一個範例是Azure OpenAI Service,它提供按使用量計費的方案,這意味著用戶根據使用服務的多少按比例收費。此外,Azure OpenAI Service在模型的能力之上提供企業級安全性和負責任的 AI 框架。
模型只是神經網路,包含參數、權重等。允許公司在本地執行,然而需要購買設備、建構延展性結構並購買許可證或使用開放原始碼模型。像 LLaMA 這樣的模型可以使用,並需要計算能力來執行模型。
如何測試和反覆運算不同模型以了解在 Azure 上的性能
一旦我們的團隊探索了當前的 LLMs 版圖並確定了一些適合其場景的良好候選者,下一步就是在他們的數據和工作負載上測試它們。這是一個通過實驗和測量進行的迭代過程。 我們在前幾段中提到的大多數模型(OpenAI 模型、開放原始碼模型如 Llama2 和 Hugging Face transformers)都可以在 Model Catalog 中的 Azure AI Studio 找到。
Azure AI Studio 是一個雲端平台,專為開發人員設計,用於建構生成式 AI 應用程式並管理整個開發生命週期 - 從實驗到評估 - 將所有 Azure AI 服務整合到一個方便的 GUI 中。Azure AI Studio 中的模型目錄使使用者能夠:
- 在目錄中找到感興趣的基礎模型 - 無論是專有的還是開放原始碼的,可以按任務、許可證或名稱進行篩選。為了提高可搜索性,這些模型被組織成集合,如 Azure OpenAI 集合、Hugging Face 集合等。
- 查看模型卡,包括預期用途和訓練數據的詳細描述、程式碼範例以及內部評估函式庫的評估結果。
- 通過模型基準窗格,比較行業中可用的模型和數據集的基準,以評估哪一個符合業務場景。
- 在自訂訓練資料上微調模型,以利用 Azure AI Studio 的實驗和追蹤功能來提升模型在特定工作負載中的表現。

- 部署原始的預訓練模型或微調版本到遠端即時推論 - 管理的計算 - 或無伺服器的 api 端點 - 隨用隨付 - 以使應用程式能夠使用它。
[!NOTE] 並非目錄中的所有模型目前都可用於微調和/或按需部署。查看模型卡以了解模型的功能和限制。
改善 LLM 結果
我們已經與我們的初創團隊探索了不同種類的 LLMs 和一個雲平台 (Azure Machine Learning),使我們能夠比較不同的模型,在測試資料上評估它們,改進性能並將它們部署在推論端點上。
但是他們什麼時候應該考慮微調模型而不是使用預訓練模型呢?是否有其他方法可以改善模型在特定工作負載上的性能?
企業可以使用多種方法從LLM中獲得所需的結果,你可以選擇不同訓練程度的不同類型模型
在生產環境中部署 LLM,具有不同的複雜性、成本和品質。以下是一些不同的方法:
-
帶有上下文的提示工程。這個想法是當你提示時提供足夠的上下文,以確保你得到所需的回應。
-
檢索增強生成(RAG)。你的資料可能存在於資料庫或網路端點。例如,為了確保這些資料或其子集在提示時被包含,你可以獲取相關資料並將其作為使用者提示的一部分。
-
微調模型。在這裡,你在自己的資料上進一步訓練模型,這使得模型更精確並能響應你的需求,但可能會很昂貴。
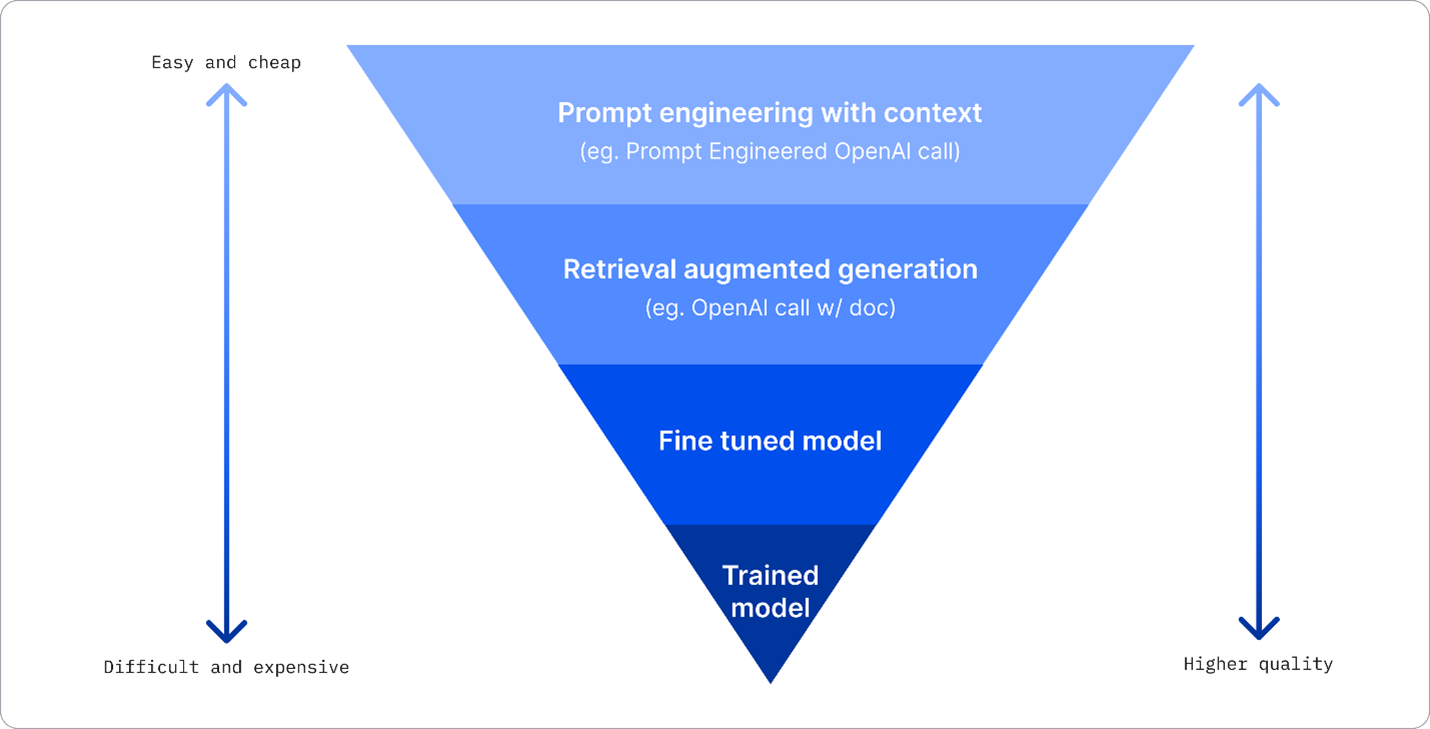
圖片來源: 四種企業部署 LLM 的方式 | Fiddler AI Blog
提示工程與上下文
預訓練的 LLMs 在一般化的自然語言任務上表現非常好,即使只用一個簡短的提示來呼叫它們,例如完成一句話或回答一個問題——所謂的「零樣本」學習。
然而,用戶越能夠框定他們的查詢,並提供詳細的請求和範例(即上下文),答案就會越準確且越接近用戶的期望。在這種情況下,如果提示中只包含一個範例,我們稱之為「單次」學習;如果包含多個範例,則稱為「少次學習」。具有上下文的提示工程是啟動時最具成本效益的方法。
檢索增強生成 (RAG)
LLMs 有一個限制,即它們只能使用訓練期間使用的資料來生成答案。這意味著它們對訓練過程之後發生的事實一無所知,並且無法訪問非公開資訊(如公司資料)。 這可以通過 RAG 技術來克服,該技術通過將外部資料以文件片段的形式增強提示,考慮提示長度限制。這由向量資料庫工具(如 Azure Vector Search)支持,這些工具從各種預定義資料來源檢索有用的片段並將它們添加到提示上下文中。
這項技術在企業沒有足夠的數據、時間或資源來微調 LLM,但仍希望提高特定工作負載的性能並降低虛構風險(即現實的神秘化或有害內容)時非常有幫助。
微調模型
微調是一種利用遷移學習將模型「適應」下游任務或解決特定問題的過程。與少量學習和RAG不同,它會生成一個新的模型,並更新權重和偏差。這需要一組訓練範例,包括單一輸入(提示)及其相關的輸出(完成)。 如果符合以下情況,這將是首選方法:
-
使用微調模型。企業希望使用微調的低性能模型(如嵌入模型)而不是高性能模型,從而達到更具成本效益和快速的解決方案。
-
考慮延遲。延遲對於特定用例很重要,因此無法使用非常長的提示詞或範例數量不符合提示詞長度限制。
-
保持最新。企業擁有大量高品質數據和真實標籤,以及保持這些數據隨時間更新所需的資源。
訓練模型
從零開始訓練一個 LLM 毫無疑問是最困難和最複雜的方法,需要大量的數據、熟練的資源和適當的計算能力。這個選項應該僅在企業有特定領域的使用案例和大量領域中心數據的情況下考慮。
知識檢查
改進 LLM 完成結果的良好方法是什麼?
- 帶上下文的提示工程
- RAG
- 微調模型
A:3, 如果你有時間和資源以及高品質的資料,微調是保持最新的更好選擇。然而,如果你想改進事情但缺乏時間,值得先考慮 RAG。
🚀 挑戰
了解更多關於如何使用 RAG來發展您的業務。
很棒的工作,繼續學習
完成本課程後,請查看我們的生成式 AI 學習集合以繼續提升您的生成式 AI 知識!
前往第3課,我們將探討如何負責任地建構生成式 AI!