建構生成式 AI 驅動的聊天應用程式

(點擊上方圖片以觀看本課的影片)
現在我們已經了解如何建構文字生成應用程式,讓我們來看看聊天應用程式。
聊天應用程式已經融入我們的日常生活,不僅僅是提供隨意交談的方式。它們是客戶服務、技術支援,甚至是複雜諮詢系統的不可或缺部分。不久前你可能就從聊天應用程式中獲得了一些幫助。隨著我們將生成式 AI 等更先進的技術整合到這些平台中,複雜性增加了,挑戰也隨之增加。
一些我們需要回答的問題是:
- 建構應用程式. 我們如何有效地建構並無縫整合這些 AI 驅動的應用程式以滿足特定的使用案例?
- 監控. 部署後,我們如何監控並確保應用程式在功能和遵循負責任 AI 的六項原則方面都能達到最高品質?
隨著我們進一步進入由自動化和無縫人機互動定義的時代,了解生成式 AI 如何改變聊天應用程式的範圍、深度和適應性變得至關重要。本課程將探討支持這些複雜系統的架構方面,深入研究為特定領域任務微調它們的方法,並評估確保負責任 AI 部署相關的指標和考量。
簡介
本課程涵蓋:
- 高效建構和整合聊天應用程式的技術。
- 如何應用自訂和微調到應用程式。
- 有效監控聊天應用程式的策略和考量。
學習目標
在這節課結束時,你將能夠:
- 描述將聊天應用程式建構並整合到現有系統中的考量因素。
- 自訂聊天應用程式以適應特定使用案例。
- 確認關鍵指標和考量因素,以有效監控並維持 AI 驅動的聊天應用程式的品質。
- 確保聊天應用程式負責任地利用 AI。
將生成式 AI 整合到聊天應用程式中
提升聊天應用程式透過生成式 AI 不僅僅是讓它們變得更智能;還在於最佳化它們的架構、性能和使用者介面,以提供高品質的使用者體驗。這涉及調查架構基礎、API 整合和使用者介面考量。本節旨在為您提供一個全面的路線圖,以便在這些複雜的領域中導航,無論您是將它們插入現有系統還是將它們建構為獨立平台。
到本節結束時,您將具備有效建構和整合聊天應用程式所需的專業知識。
聊天機器人或聊天應用程式?
在我們深入建構聊天應用程式之前,讓我們比較一下「聊天機器人」和「AI 驅動的聊天應用程式」,它們具有不同的角色和功能。聊天機器人的主要目的是自動化特定的對話任務,例如回答常見問題或追蹤套件。它通常由基於規則的邏輯或複雜的 AI 演算法控制。相比之下,AI 驅動的聊天應用程式是一個更為廣泛的環境,旨在促進各種形式的數位通信,例如文字、語音和影片聊天。其定義特徵是整合了一個生成式 AI 模型,模擬細緻入微的類人對話,根據各種輸入和上下文線索生成回應。生成式 AI 驅動的聊天應用程式可以參與開放領域的討論,適應不斷變化的對話上下文,甚至產生創意或複雜的對話。
下表概述了關鍵差異和相似之處,以幫助我們了解它們在數位通信中的獨特角色。
| 聊天機器人 | 生成式 AI 驅動的聊天應用程式 |
|---|---|
| 任務導向和基於規則 | 情境感知 |
| 通常整合到更大的系統中 | 可以承載一個或多個聊天機器人 |
| 限於程式化的功能 | 包含生成式 AI 模型 |
| 專門且結構化的互動 | 能夠進行開放領域的討論 |
利用 SDK 和 API 的內建功能
在建構聊天應用程式時,一個很好的第一步是評估現有的資源。使用 SDK 和 API 來建構聊天應用程式是一種有利的策略,原因有很多。通過整合文件完善的 SDK 和 API,你正在策略性地為你的應用程式定位長期成功,解決延展性和維護問題。
- 加速開發過程並減少開銷: 依賴預建的功能而不是自行建構昂貴的過程,讓你可以專注於應用程式的其他方面,例如商業邏輯。
- 更好的性能: 當從頭開始建構功能時,你最終會問自己「它如何延展?這個應用程式能夠處理突然湧入的使用者嗎?」良好維護的 SDK 和 API 通常內建了這些問題的解決方案。
- 更容易維護: 更新和改進更容易管理,因為大多數 API 和 SDK 只需在新版本發布時更新函式庫。
- 接觸尖端技術: 利用經過微調和訓練的大量數據集的模型,為你的應用程式提供自然語言能力。
存取 SDK 或 API 的功能通常涉及獲取使用所提供服務的許可,這通常是通過使用唯一的金鑰或身份驗證令牌來實現的。我們將使用 OpenAI Python 函式庫來探索這看起來是什麼樣子的。你也可以在以下的 OpenAI 筆記本 或 Azure OpenAI Services 筆記本 中自行嘗試這一課程。
import os
from openai import OpenAI
API_KEY = os.getenv("OPENAI_API_KEY","")
client = OpenAI(
api_key=API_KEY
)
chat_completion = client.chat.completions.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "為生成式 AI 的聊天應用程式建議兩個教學課程標題。"}])
上述範例使用 GPT-3.5 Turbo 模型來完成提示,但請注意在此之前已設定 API 金鑰。如果未設定金鑰,您將收到錯誤。
使用者體驗 (UX)
一般的使用者體驗原則適用於聊天應用程式,但由於涉及機器學習元件,這裡有一些額外的考量變得特別重要。
- 解決歧義的機制: 生成式 AI 模型偶爾會生成模糊的答案。允許用戶要求澄清的功能在遇到這個問題時會很有幫助。
- 上下文保留: 高級生成式 AI 模型具有記住對話上下文的能力,這對用戶體驗來說是必要的資產。讓用戶能夠控制和管理上下文可以改善用戶體驗,但也引入了保留敏感用戶資訊的風險。對於這些資訊存儲多長時間的考量,例如引入保留政策,可以在上下文需求與隱私之間取得平衡。
- 個性化: 具有學習和適應能力的 AI 模型為用戶提供了個性化的體驗。通過用戶檔案等功能定制用戶體驗,不僅讓用戶感到被理解,還有助於他們尋找特定答案,創造更高效和滿意的互動。
例如在 OpenAI 的 ChatGPT 中的"自訂指示"設定就是一個這樣的個人化範例。它允許你提供關於你自己的資訊,這些資訊可能是你的提示的重要背景。這裡是一個自訂指示的範例。
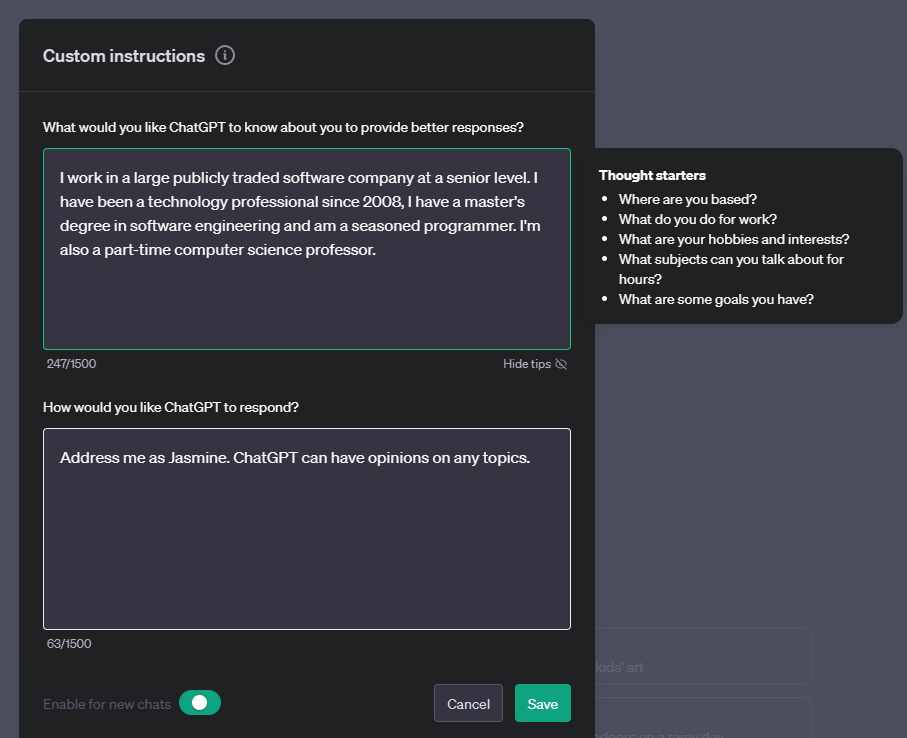
這個「設定檔」提示ChatGPT建立一個關於鏈結串列的課程計劃。請注意,ChatGPT會考慮到使用者可能基於她的經驗需要更深入的課程計劃。

微軟的大型語言模型系統訊息框架
Microsoft has provided guidance for writing effective system messages when generating responses from LLMs broken down into 4 areas:
- 定義模型的目標對象,以及其能力和限制。
- 定義模型的輸出格式。
- 提供展示模型預期行為的具體範例。
- 提供額外的行為防護措施。
無障礙性
無論使用者是否有視覺、聽覺、運動或認知障礙,一個設計良好的聊天應用程式應該對所有人都可用。以下列表分解了旨在提高各種使用者障礙可及性的特定功能。
- 視障功能: 高對比主題和可調整大小的文字,螢幕閱讀器相容性。
- 聽障功能: 文字轉語音和語音轉文字函式,音訊通知的視覺提示。
- 肢體障礙功能: 鍵盤導航支援,語音命令。
- 認知障礙功能: 簡化語言選項。
自訂和微調領域特定語言模型
想像一個聊天應用程式,它能理解你公司的行話並預測其用戶群常見的特定查詢。有幾種方法值得一提:
- 利用DSL模型。DSL代表領域專用語言。您可以利用在特定領域訓練的所謂DSL模型來理解其概念和情境。
- 應用微調。微調是使用特定資料進一步訓練模型的過程。
自訂: 使用 DSL
利用領域專用語言模型(DSL Models)可以通過提供專業的、上下文相關的互動來增強用戶參與度。這是一種訓練或微調以理解和生成與特定領域、行業或主題相關文本的模型。使用DSL模型的選項可以從從頭開始訓練一個,到通過SDK和API使用現有的模型。另一個選項是微調,這涉及採用現有的預訓練模型並將其調整為特定領域。
自訂: 套用微調
微調通常在預訓練模型在專門領域或特定任務中表現不佳時考慮。
例如,醫療查詢非常複雜,需要大量的上下文。當醫療專業人員診斷患者時,會基於多種因素,如生活方式或既存病況,甚至可能依賴最近的醫學期刊來驗證其診斷。在這種細微的情況下,通用的 AI 聊天應用程式不能成為可靠的來源。
情境: 一個醫療應用程序
考慮一個聊天應用程式,旨在通過提供治療指南、藥物相互作用或最新研究結果的快速參考來協助醫療從業人員。
一個通用模型可能足以回答基本的醫療問題或提供一般建議,但可能在以下方面存在困難:
- 高度特定或複雜的案例。例如,神經科醫生可能會問應用程式:「目前管理兒童患者藥物抗性癲癇的最佳做法是什麼?」
- 缺乏最新進展。通用模型可能難以提供包含神經學和藥理學最新進展的當前答案。
在這些情況下,使用專門的醫療數據集對模型進行微調可以顯著提高其更準確和可靠地處理這些複雜醫療問題的能力。這需要訪問大量且相關的數據集,這些數據集代表了需要解決的特定領域挑戰和問題。
高品質 AI 驅動聊天體驗的考量因素
本節概述了「高品質」聊天應用程式的標準,包括捕捉可操作的指標和遵循負責任地利用 AI 技術的框架。
關鍵指標
為了維持應用程式的高品質效能,追蹤關鍵指標和考量因素是必不可少的。這些測量不僅確保應用程式的功能性,還評估 AI 模型和使用者體驗的品質。以下是一份涵蓋基本、AI 和使用者體驗指標的清單,供參考。
| Metric | Definition | Considerations for Chat Developer |
|---|---|---|
| Uptime | 測量應用程式運行和用戶可訪問的時間。 | 你將如何最大限度地減少停機時間? |
| Response Time | 應用程式回應用戶查詢所需的時間。 | 你如何優化查詢處理以改善回應時間? |
| Precision | 真陽性預測數量與總陽性預測數量的比率。 | 你將如何驗證模型的精確度? |
| Recall (Sensitivity) | 真陽性預測數量與實際陽性數量的比率。 | 你將如何測量和改善召回率? |
| F1 Score | 精確度和召回率的調和平均數,平衡兩者之間的權衡。 | 你的目標 F1 Score 是什麼?你將如何平衡精確度和召回率? |
| Perplexity | 測量模型預測的概率分佈與實際數據分佈的對齊程度。 | 你將如何減少困惑度? |
| User Satisfaction Metrics | 測量用戶對應用程式的感知。通常通過調查收集。 | 你將多頻繁地收集用戶反饋?你將如何根據反饋進行調整? |
| Error Rate | 模型在理解或輸出時犯錯的比率。 | 你有什麼策略來減少錯誤率? |
| Retraining Cycles | 模型更新以納入新數據和見解的頻率。 | 你將多頻繁地重新訓練模型?什麼會觸發重新訓練週期? |
| Anomaly Detection | 用於識別不符合預期行為的異常模式的工具和技術。 | 你將如何應對異常? |
在聊天應用程式中實現負責任的 AI 實踐
Microsoft 的負責任 AI 方法已經確立了六項應該指導 AI 開發和使用的原則。以下是這些原則、它們的定義以及聊天開發者應該考慮的事項和為什麼他們應該認真對待這些事項。
| 原則 | 微軟的定義 | 聊天應用程式開發者的考量 | 為什麼這很重要 |
|---|---|---|---|
| 公平性 | AI 系統應該公平對待所有人。 | 確保聊天應用程式不會基於用戶資料進行歧視。 | 建立用戶之間的信任和包容性;避免法律後果。 |
| 可靠性和安全性 | AI 系統應該可靠且安全地運行。 | 實施測試和故障保護以最小化錯誤和風險。 | 確保用戶滿意度並防止潛在的傷害。 |
| 隱私和安全 | AI 系統應該是安全的並尊重隱私。 | 實施強加密和資料保護措施。 | 保護敏感用戶資料並遵守隱私法規。 |
| 包容性 | AI 系統應該賦予每個人權力並讓人們參與。 | 設計對多元觀眾可訪問且易於使用的 UI/UX。 | 確保更廣泛的人群能有效使用應用程式。 |
| 透明性 | AI 系統應該是可理解的。 | 提供清晰的文件和 AI 回應的理由。 | 用戶更可能信任一個他們能理解決策過程的系統。 |
| 問責性 | 人們應該對 AI 系統負責。 | 建立明確的審計和改進 AI 決策的過程。 | 在出錯時能夠持續改進和採取糾正措施。 |
作業
請參閱assignment它將帶你完成一系列的練習,從執行你的第一個聊天提示,到分類和摘要文本等等。請注意,這些作業有不同的程式語言版本!
很棒的工作!繼續這段旅程
完成本課程後,請查看我們的生成式 AI 學習集合以繼續提升您的生成式 AI 知識!
前往第8課,看看如何開始建構搜尋應用程式!